本文介绍二叉堆,二叉堆就是通常我们所说的数据结构"堆"中的一种。和以往一样,本文会先对二叉堆的理论知识进行简单介绍,然后给出C语言的实现。后续再分别给出C++和Java版本的实现;实现的语言虽不同,但是原理如出一辙,选择其中之一进行了解即可。若文章有错误或不足的地方,请不吝指出!
堆和二叉堆的介绍
1. 堆的定义
堆(heap),这里所说的堆是数据结构中的堆,而不是内存模型中的堆。堆通常是一个可以被看做一棵树,它满足下列性质:
- [性质一] 堆中某个节点的值总是不大于或不小于其父节点的值;
- [性质二] 堆总是一棵完全树。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、左倾堆、斜堆、斐波那契堆等等。
2. 二叉堆的定义
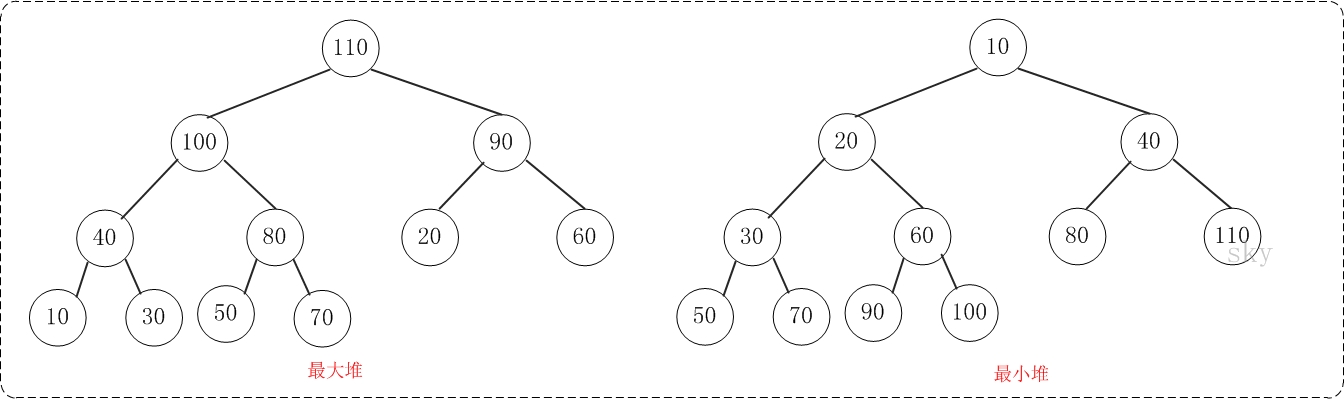
二叉堆是完全二元树或者是近似完全二元树,它分为两种:最大堆和最小堆。示意图如下:
最大堆:父结点的键值总是大于或等于任何一个子节点的键值;
最小堆:父结点的键值总是小于或等于任何一个子节点的键值。
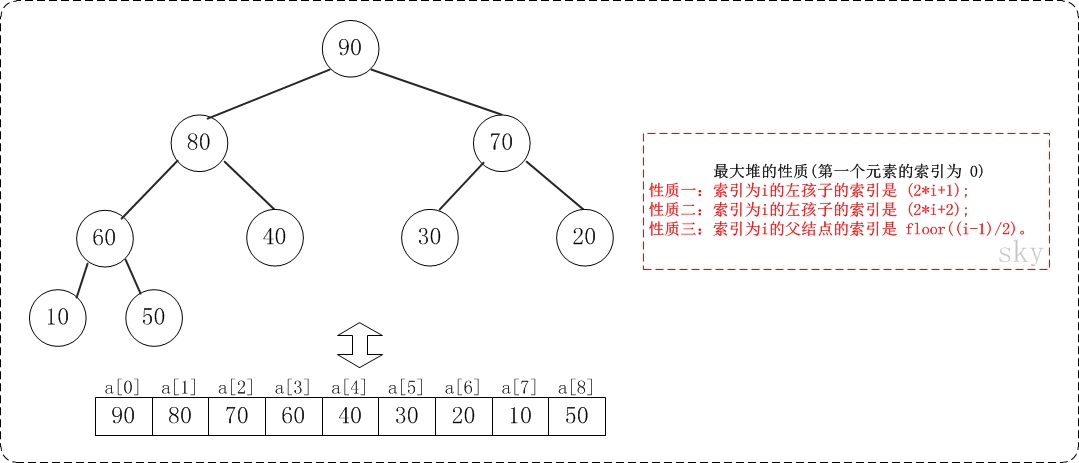
二叉堆一般都通过"数组"来实现。数组实现的二叉堆,父节点和子节点的位置存在一定的关系。有时候,我们将"二叉堆的第一个元素"放在数组索引0的位置,有时候放在1的位置。当然,它们的本质一样(都是二叉堆),知识实现上稍微有一丁点区别。
假设"第一个元素"在数组中的索引为 0 的话,则父节点和子节点的位置关系如下:
(01) 索引为i的左孩子的索引是 (2*i+1);
(02) 索引为i的左孩子的索引是 (2*i+2);
(03) 索引为i的父结点的索引是 floor((i-1)/2)。
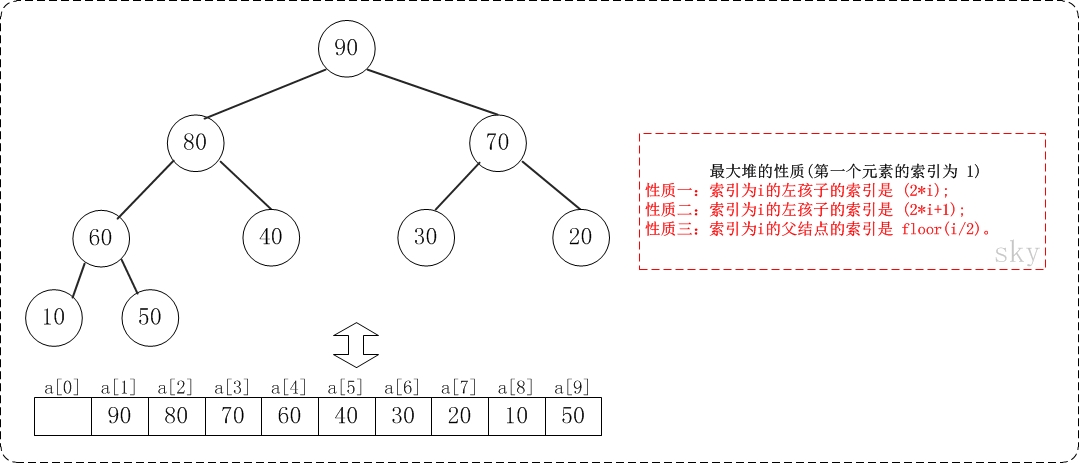
假设"第一个元素"在数组中的索引为 1 的话,则父节点和子节点的位置关系如下:
(01) 索引为i的左孩子的索引是 (2*i);
(02) 索引为i的左孩子的索引是 (2*i+1);
(03) 索引为i的父结点的索引是 floor(i/2)。
注意:本文二叉堆的实现统统都是采用"二叉堆第一个元素在数组索引为0"的方式!
二叉堆的图文解析
在前面,我们已经了解到:"最大堆"和"最小堆"是对称关系。这也意味着,了解其中之一即可。本文是以"最大堆"来进行介绍的。
二叉堆的核心是"添加节点"和"删除节点",理解这两个算法,二叉堆也就基本掌握了。下面对它们进行介绍。
1. 添加
假设在最大堆[90,80,70,60,40,30,20,10,50]种添加85,需要执行的步骤如下:
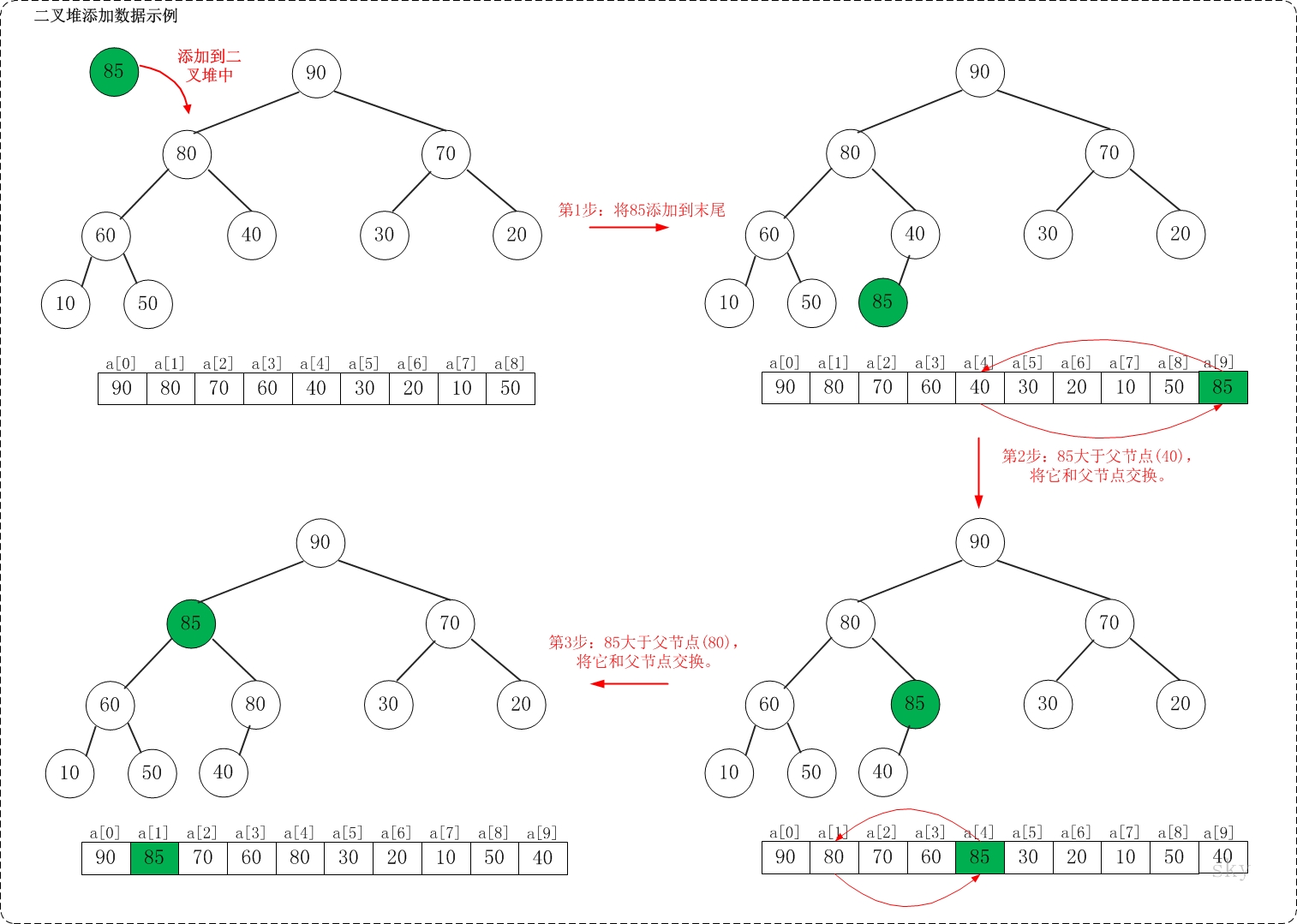
如上图所示,当向最大堆中添加数据时:先将数据加入到最大堆的最后,然后尽可能把这个元素往上挪,直到挪不动为止!
将85添加到[90,80,70,60,40,30,20,10,50]中后,最大堆变成了[90,85,70,60,80,30,20,10,50,40]。
最大堆的插入代码
/*
* 将data插入到二叉堆中
*
* 返回值:
* 0,表示成功
* -1,表示失败
*/
int maxheap_insert(int data)
{
// 如果"堆"已满,则返回
if(m_size == m_capacity)
return -1;
m_heap[m_size] = data; // 将"数组"插在表尾
maxheap_filterup(m_size); // 向上调整堆
m_size++; // 堆的实际容量+1
return 0;
}
maxheap_insert(data)的作用:将数据data添加到最大堆中。当堆已满的时候,添加失败;否则data添加到最大堆的末尾。然后通过上调算法重新调整数组,使之重新成为最大堆。
2. 删除
假设从最大堆[90,85,70,60,80,30,20,10,50,40]中删除90,需要执行的步骤如下:
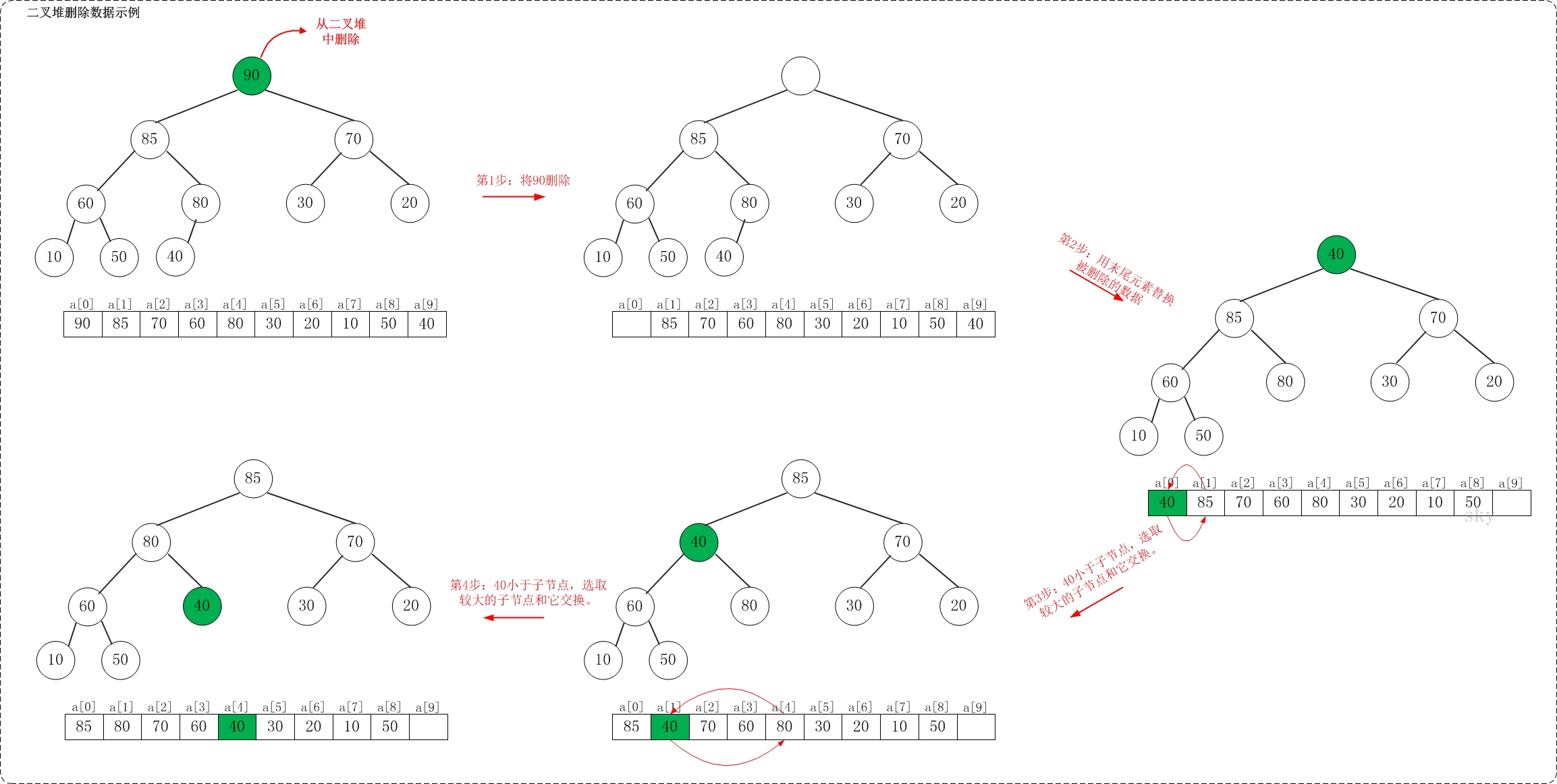
从[90,85,70,60,80,30,20,10,50,40]删除90之后,最大堆变成了[85,80,70,60,40,30,20,10,50]。
如上图所示,当从最大堆中删除数据时:先删除该数据,然后用最大堆中最后一个的元素插入这个空位;接着,把这个“空位”尽量往上挪,直到剩余的数据变成一个最大堆。
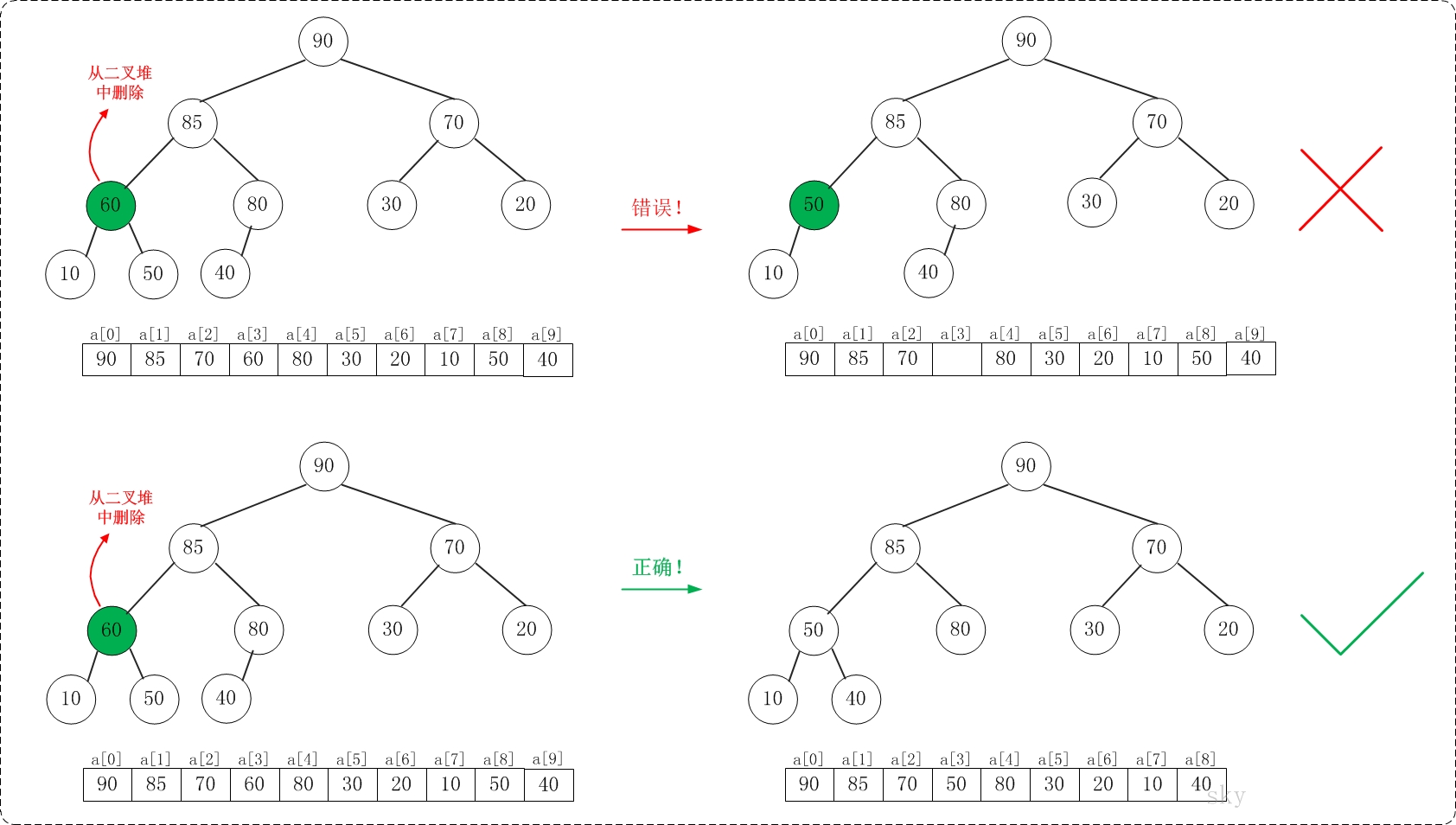
注意:考虑从最大堆[90,85,70,60,80,30,20,10,50,40]中删除70,执行的步骤不能单纯的用它的字节点来替换;而必须考虑到"替换后的树仍然要是最大堆"!
最大堆的删除代码
/*
* 删除最大堆中的data
*
* 返回值:
* 0,成功
* -1,失败
*/
int maxheap_remove(int data)
{
int index;
// 如果"堆"已空,则返回-1
if(m_size == 0)
return -1;
// 获取data在数组中的索引
index = get_index(data);
if (index==-1)
return -1;
m_heap[index] = m_heap[--m_size]; // 用最后元素填补
maxheap_filterdown(index, m_size-1); // 从index位置开始自上向下调整为最大堆
return 0;
}
maxheap_remove(data)的作用:从最大堆中删除数据data。
当堆已经为空的时候,删除失败;否则查处data在最大堆数组中的位置。找到之后,先用最后的元素来替换被删除元素;然后通过下调算法重新调整数组,使之重新成为最大堆。
二叉堆的实现源码和测试包括
二叉堆的源码包含了"最大堆"和"最小堆"。