本章对Java.util.concurrent包中的ConcurrentSkipListMap类进行详细的介绍。
目录
1. ConcurrentSkipListMap介绍
2. ConcurrentSkipListMap原理和数据结构
3. ConcurrentSkipListMap函数列表
4. ConcurrentSkipListMap源码分析(JDK1.7.0_40版本)
4.1 添加
4.2 删除
4.3 获取
5. ConcurrentSkipListMap示例
1. ConcurrentSkipListMap介绍
ConcurrentSkipListMap是线程安全的有序的哈希表,适用于高并发的场景。
ConcurrentSkipListMap和TreeMap,它们虽然都是有序的哈希表。 但是,
第一,它们的线程安全机制不同,TreeMap是非线程安全的,而ConcurrentSkipListMap是线程安全的。
第二,ConcurrentSkipListMap是通过跳表实现的,而TreeMap是通过红黑树实现的。
关于跳表(Skip List),它是平衡树的一种替代的数据结构,但是和红黑树不相同的是,跳表对于树的平衡的实现是基于一种随机化的算法的,这样也就是说跳表的插入和删除的工作是比较简单的。
2. ConcurrentSkipListMap原理和数据结构
ConcurrentSkipListMap的数据结构,如下图所示:
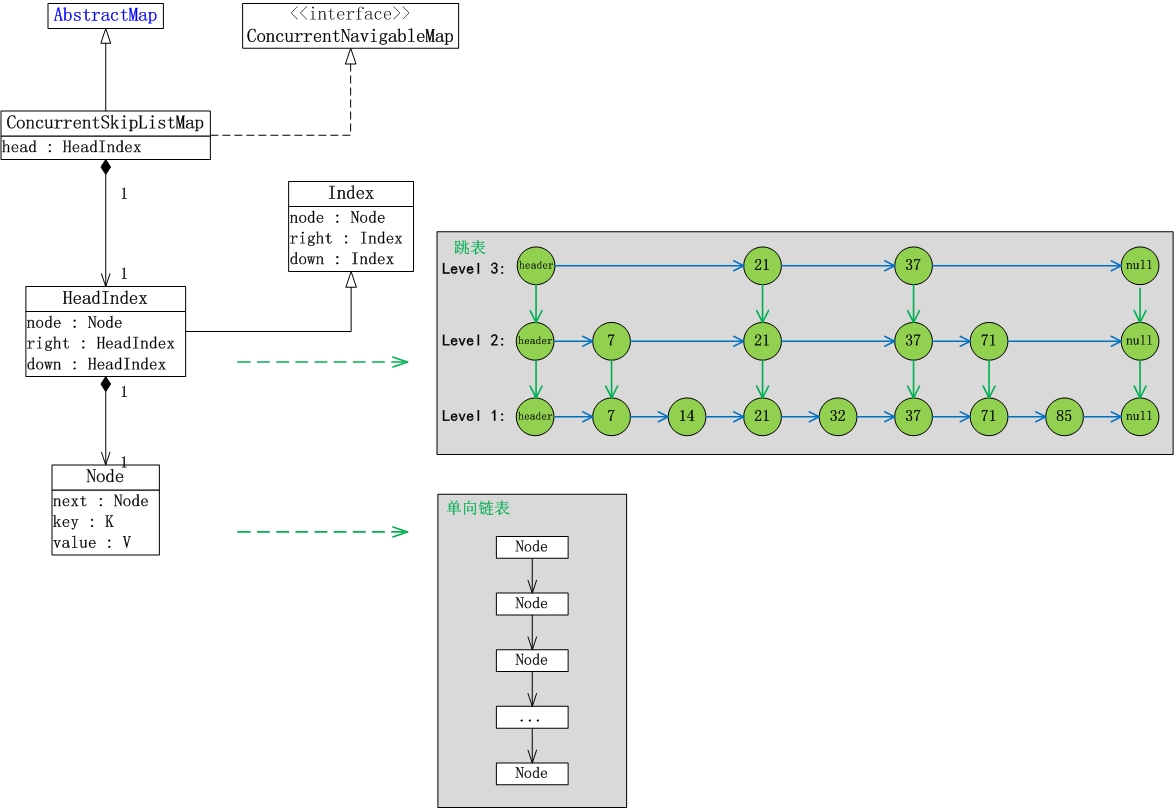
说明:
先以数据“7,14,21,32,37,71,85”序列为例,来对跳表进行简单说明。
跳表分为许多层(level),每一层都可以看作是数据的索引,这些索引的意义就是加快跳表查找数据速度。每一层的数据都是有序的,上一层数据是下一层数据的子集,并且第一层(level 1)包含了全部的数据;层次越高,跳跃性越大,包含的数据越少。
跳表包含一个表头,它查找数据时,是从上往下,从左往右进行查找。现在“需要找出值为32的节点”为例,来对比说明跳表和普遍的链表。
情况1:链表中查找“32”节点
路径如下图所示:

需要4步(红色部分表示路径)。
情况2:跳表中查找“32”节点
路径如下图1-03所示:
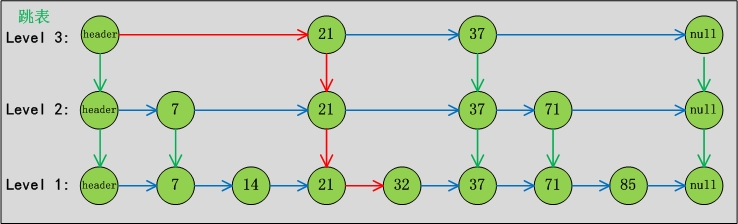
忽略索引垂直线路上路径的情况下,只需要2步(红色部分表示路径)。
下面说说Java中ConcurrentSkipListMap的数据结构。
(01) ConcurrentSkipListMap继承于AbstractMap类,也就意味着它是一个哈希表。
(02) Index是ConcurrentSkipListMap的内部类,它与“跳表中的索引相对应”。HeadIndex继承于Index,ConcurrentSkipListMap中含有一个HeadIndex的对象head,head是“跳表的表头”。
(03) Index是跳表中的索引,它包含“右索引的指针(right)”,“下索引的指针(down)”和“哈希表节点node”。node是Node的对象,Node也是ConcurrentSkipListMap中的内部类。
3. ConcurrentSkipListMap函数列表
// 构造一个新的空映射,该映射按照键的自然顺序进行排序。
ConcurrentSkipListMap()
// 构造一个新的空映射,该映射按照指定的比较器进行排序。
ConcurrentSkipListMap(Comparator<? super K> comparator)
// 构造一个新映射,该映射所包含的映射关系与给定映射包含的映射关系相同,并按照键的自然顺序进行排序。
ConcurrentSkipListMap(Map<? extends K,? extends V> m)
// 构造一个新映射,该映射所包含的映射关系与指定的有序映射包含的映射关系相同,使用的顺序也相同。
ConcurrentSkipListMap(SortedMap<K,? extends V> m)
// 返回与大于等于给定键的最小键关联的键-值映射关系;如果不存在这样的条目,则返回 null。
Map.Entry<K,V> ceilingEntry(K key)
// 返回大于等于给定键的最小键;如果不存在这样的键,则返回 null。
K ceilingKey(K key)
// 从此映射中移除所有映射关系。
void clear()
// 返回此 ConcurrentSkipListMap 实例的浅表副本。
ConcurrentSkipListMap<K,V> clone()
// 返回对此映射中的键进行排序的比较器;如果此映射使用键的自然顺序,则返回 null。
Comparator<? super K> comparator()
// 如果此映射包含指定键的映射关系,则返回 true。
boolean containsKey(Object key)
// 如果此映射为指定值映射一个或多个键,则返回 true。
boolean containsValue(Object value)
// 返回此映射中所包含键的逆序 NavigableSet 视图。
NavigableSet<K> descendingKeySet()
// 返回此映射中所包含映射关系的逆序视图。
ConcurrentNavigableMap<K,V> descendingMap()
// 返回此映射中所包含的映射关系的 Set 视图。
Set<Map.Entry<K,V>> entrySet()
// 比较指定对象与此映射的相等性。
boolean equals(Object o)
// 返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> firstEntry()
// 返回此映射中当前第一个(最低)键。
K firstKey()
// 返回与小于等于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。
Map.Entry<K,V> floorEntry(K key)
// 返回小于等于给定键的最大键;如果不存在这样的键,则返回 null。
K floorKey(K key)
// 返回指定键所映射到的值;如果此映射不包含该键的映射关系,则返回 null。
V get(Object key)
// 返回此映射的部分视图,其键值严格小于 toKey。
ConcurrentNavigableMap<K,V> headMap(K toKey)
// 返回此映射的部分视图,其键小于(或等于,如果 inclusive 为 true)toKey。
ConcurrentNavigableMap<K,V> headMap(K toKey, boolean inclusive)
// 返回与严格大于给定键的最小键关联的键-值映射关系;如果不存在这样的键,则返回 null。
Map.Entry<K,V> higherEntry(K key)
// 返回严格大于给定键的最小键;如果不存在这样的键,则返回 null。
K higherKey(K key)
// 如果此映射未包含键-值映射关系,则返回 true。
boolean isEmpty()
// 返回此映射中所包含键的 NavigableSet 视图。
NavigableSet<K> keySet()
// 返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> lastEntry()
// 返回映射中当前最后一个(最高)键。
K lastKey()
// 返回与严格小于给定键的最大键关联的键-值映射关系;如果不存在这样的键,则返回 null。
Map.Entry<K,V> lowerEntry(K key)
// 返回严格小于给定键的最大键;如果不存在这样的键,则返回 null。
K lowerKey(K key)
// 返回此映射中所包含键的 NavigableSet 视图。
NavigableSet<K> navigableKeySet()
// 移除并返回与此映射中的最小键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> pollFirstEntry()
// 移除并返回与此映射中的最大键关联的键-值映射关系;如果该映射为空,则返回 null。
Map.Entry<K,V> pollLastEntry()
// 将指定值与此映射中的指定键关联。
V put(K key, V value)
// 如果指定键已经不再与某个值相关联,则将它与给定值关联。
V putIfAbsent(K key, V value)
// 从此映射中移除指定键的映射关系(如果存在)。
V remove(Object key)
// 只有目前将键的条目映射到给定值时,才移除该键的条目。
boolean remove(Object key, Object value)
// 只有目前将键的条目映射到某一值时,才替换该键的条目。
V replace(K key, V value)
// 只有目前将键的条目映射到给定值时,才替换该键的条目。
boolean replace(K key, V oldValue, V newValue)
// 返回此映射中的键-值映射关系数。
int size()
// 返回此映射的部分视图,其键的范围从 fromKey 到 toKey。
ConcurrentNavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive)
// 返回此映射的部分视图,其键值的范围从 fromKey(包括)到 toKey(不包括)。
ConcurrentNavigableMap<K,V> subMap(K fromKey, K toKey)
// 返回此映射的部分视图,其键大于等于 fromKey。
ConcurrentNavigableMap<K,V> tailMap(K fromKey)
// 返回此映射的部分视图,其键大于(或等于,如果 inclusive 为 true)fromKey。
ConcurrentNavigableMap<K,V> tailMap(K fromKey, boolean inclusive)
// 返回此映射中所包含值的 Collection 视图。
Collection<V> values()
4. ConcurrentSkipListMap源码分析(JDK1.7.0_40版本)
ConcurrentSkipListMap.java的完整源码如下:
package java.util.concurrent;
import java.util.*;
import java.util.concurrent.atomic.*;
/**
* A scalable concurrent {@link ConcurrentNavigableMap} implementation.
* The map is sorted according to the {@linkplain Comparable natural
* ordering} of its keys, or by a {@link Comparator} provided at map
* creation time, depending on which constructor is used.
*
* <p>This class implements a concurrent variant of <a
* href="http://en.wikipedia.org/wiki/Skip_list" target="_top">SkipLists</a>
* providing expected average <i>log(n)</i> time cost for the
* <tt>containsKey</tt>, <tt>get</tt>, <tt>put</tt> and
* <tt>remove</tt> operations and their variants. Insertion, removal,
* update, and access operations safely execute concurrently by
* multiple threads. Iterators are <i>weakly consistent</i>, returning
* elements reflecting the state of the map at some point at or since
* the creation of the iterator. They do <em>not</em> throw {@link
* ConcurrentModificationException}, and may proceed concurrently with
* other operations. Ascending key ordered views and their iterators
* are faster than descending ones.
*
* <p>All <tt>Map.Entry</tt> pairs returned by methods in this class
* and its views represent snapshots of mappings at the time they were
* produced. They do <em>not</em> support the <tt>Entry.setValue</tt>
* method. (Note however that it is possible to change mappings in the
* associated map using <tt>put</tt>, <tt>putIfAbsent</tt>, or
* <tt>replace</tt>, depending on exactly which effect you need.)
*
* <p>Beware that, unlike in most collections, the <tt>size</tt>
* method is <em>not</em> a constant-time operation. Because of the
* asynchronous nature of these maps, determining the current number
* of elements requires a traversal of the elements, and so may report
* inaccurate results if this collection is modified during traversal.
* Additionally, the bulk operations <tt>putAll</tt>, <tt>equals</tt>,
* <tt>toArray</tt>, <tt>containsValue</tt>, and <tt>clear</tt> are
* <em>not</em> guaranteed to be performed atomically. For example, an
* iterator operating concurrently with a <tt>putAll</tt> operation
* might view only some of the added elements.
*
* <p>This class and its views and iterators implement all of the
* <em>optional</em> methods of the {@link Map} and {@link Iterator}
* interfaces. Like most other concurrent collections, this class does
* <em>not</em> permit the use of <tt>null</tt> keys or values because some
* null return values cannot be reliably distinguished from the absence of
* elements.
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @author Doug Lea
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
* @since 1.6
*/
public class ConcurrentSkipListMap<K,V> extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>,
Cloneable,
java.io.Serializable {
/*
* This class implements a tree-like two-dimensionally linked skip
* list in which the index levels are represented in separate
* nodes from the base nodes holding data. There are two reasons
* for taking this approach instead of the usual array-based
* structure: 1) Array based implementations seem to encounter
* more complexity and overhead 2) We can use cheaper algorithms
* for the heavily-traversed index lists than can be used for the
* base lists. Here's a picture of some of the basics for a
* possible list with 2 levels of index:
*
* Head nodes Index nodes
* +-+ right +-+ +-+
* |2|---------------->| |--------------------->| |->null
* +-+ +-+ +-+
* | down | |
* v v v
* +-+ +-+ +-+ +-+ +-+ +-+
* |1|----------->| |->| |------>| |----------->| |------>| |->null
* +-+ +-+ +-+ +-+ +-+ +-+
* v | | | | |
* Nodes next v v v v v
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
* | |->|A|->|B|->|C|->|D|->|E|->|F|->|G|->|H|->|I|->|J|->|K|->null
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
*
* The base lists use a variant of the HM linked ordered set
* algorithm. See Tim Harris, "A pragmatic implementation of
* non-blocking linked lists"
* http://www.cl.cam.ac.uk/~tlh20/publications.html and Maged
* Michael "High Performance Dynamic Lock-Free Hash Tables and
* List-Based Sets"
* http://www.research.ibm.com/people/m/michael/pubs.htm. The
* basic idea in these lists is to mark the "next" pointers of
* deleted nodes when deleting to avoid conflicts with concurrent
* insertions, and when traversing to keep track of triples
* (predecessor, node, successor) in order to detect when and how
* to unlink these deleted nodes.
*
* Rather than using mark-bits to mark list deletions (which can
* be slow and space-intensive using AtomicMarkedReference), nodes
* use direct CAS'able next pointers. On deletion, instead of
* marking a pointer, they splice in another node that can be
* thought of as standing for a marked pointer (indicating this by
* using otherwise impossible field values). Using plain nodes
* acts roughly like "boxed" implementations of marked pointers,
* but uses new nodes only when nodes are deleted, not for every
* link. This requires less space and supports faster
* traversal. Even if marked references were better supported by
* JVMs, traversal using this technique might still be faster
* because any search need only read ahead one more node than
* otherwise required (to check for trailing marker) rather than
* unmasking mark bits or whatever on each read.
*
* This approach maintains the essential property needed in the HM
* algorithm of changing the next-pointer of a deleted node so
* that any other CAS of it will fail, but implements the idea by
* changing the pointer to point to a different node, not by
* marking it. While it would be possible to further squeeze
* space by defining marker nodes not to have key/value fields, it
* isn't worth the extra type-testing overhead. The deletion
* markers are rarely encountered during traversal and are
* normally quickly garbage collected. (Note that this technique
* would not work well in systems without garbage collection.)
*
* In addition to using deletion markers, the lists also use
* nullness of value fields to indicate deletion, in a style
* similar to typical lazy-deletion schemes. If a node's value is
* null, then it is considered logically deleted and ignored even
* though it is still reachable. This maintains proper control of
* concurrent replace vs delete operations -- an attempted replace
* must fail if a delete beat it by nulling field, and a delete
* must return the last non-null value held in the field. (Note:
* Null, rather than some special marker, is used for value fields
* here because it just so happens to mesh with the Map API
* requirement that method get returns null if there is no
* mapping, which allows nodes to remain concurrently readable
* even when deleted. Using any other marker value here would be
* messy at best.)
*
* Here's the sequence of events for a deletion of node n with
* predecessor b and successor f, initially:
*
* +------+ +------+ +------+
* ... | b |------>| n |----->| f | ...
* +------+ +------+ +------+
*
* 1. CAS n's value field from non-null to null.
* From this point on, no public operations encountering
* the node consider this mapping to exist. However, other
* ongoing insertions and deletions might still modify
* n's next pointer.
*
* 2. CAS n's next pointer to point to a new marker node.
* From this point on, no other nodes can be appended to n.
* which avoids deletion errors in CAS-based linked lists.
*
* +------+ +------+ +------+ +------+
* ... | b |------>| n |----->|marker|------>| f | ...
* +------+ +------+ +------+ +------+
*
* 3. CAS b's next pointer over both n and its marker.
* From this point on, no new traversals will encounter n,
* and it can eventually be GCed.
* +------+ +------+
* ... | b |----------------------------------->| f | ...
* +------+ +------+
*
* A failure at step 1 leads to simple retry due to a lost race
* with another operation. Steps 2-3 can fail because some other
* thread noticed during a traversal a node with null value and
* helped out by marking and/or unlinking. This helping-out
* ensures that no thread can become stuck waiting for progress of
* the deleting thread. The use of marker nodes slightly
* complicates helping-out code because traversals must track
* consistent reads of up to four nodes (b, n, marker, f), not
* just (b, n, f), although the next field of a marker is
* immutable, and once a next field is CAS'ed to point to a
* marker, it never again changes, so this requires less care.
*
* Skip lists add indexing to this scheme, so that the base-level
* traversals start close to the locations being found, inserted
* or deleted -- usually base level traversals only traverse a few
* nodes. This doesn't change the basic algorithm except for the
* need to make sure base traversals start at predecessors (here,
* b) that are not (structurally) deleted, otherwise retrying
* after processing the deletion.
*
* Index levels are maintained as lists with volatile next fields,
* using CAS to link and unlink. Races are allowed in index-list
* operations that can (rarely) fail to link in a new index node
* or delete one. (We can't do this of course for data nodes.)
* However, even when this happens, the index lists remain sorted,
* so correctly serve as indices. This can impact performance,
* but since skip lists are probabilistic anyway, the net result
* is that under contention, the effective "p" value may be lower
* than its nominal value. And race windows are kept small enough
* that in practice these failures are rare, even under a lot of
* contention.
*
* The fact that retries (for both base and index lists) are
* relatively cheap due to indexing allows some minor
* simplifications of retry logic. Traversal restarts are
* performed after most "helping-out" CASes. This isn't always
* strictly necessary, but the implicit backoffs tend to help
* reduce other downstream failed CAS's enough to outweigh restart
* cost. This worsens the worst case, but seems to improve even
* highly contended cases.
*
* Unlike most skip-list implementations, index insertion and
* deletion here require a separate traversal pass occuring after
* the base-level action, to add or remove index nodes. This adds
* to single-threaded overhead, but improves contended
* multithreaded performance by narrowing interference windows,
* and allows deletion to ensure that all index nodes will be made
* unreachable upon return from a public remove operation, thus
* avoiding unwanted garbage retention. This is more important
* here than in some other data structures because we cannot null
* out node fields referencing user keys since they might still be
* read by other ongoing traversals.
*
* Indexing uses skip list parameters that maintain good search
* performance while using sparser-than-usual indices: The
* hardwired parameters k=1, p=0.5 (see method randomLevel) mean
* that about one-quarter of the nodes have indices. Of those that
* do, half have one level, a quarter have two, and so on (see
* Pugh's Skip List Cookbook, sec 3.4). The expected total space
* requirement for a map is slightly less than for the current
* implementation of java.util.TreeMap.
*
* Changing the level of the index (i.e, the height of the
* tree-like structure) also uses CAS. The head index has initial
* level/height of one. Creation of an index with height greater
* than the current level adds a level to the head index by
* CAS'ing on a new top-most head. To maintain good performance
* after a lot of removals, deletion methods heuristically try to
* reduce the height if the topmost levels appear to be empty.
* This may encounter races in which it possible (but rare) to
* reduce and "lose" a level just as it is about to contain an
* index (that will then never be encountered). This does no
* structural harm, and in practice appears to be a better option
* than allowing unrestrained growth of levels.
*
* The code for all this is more verbose than you'd like. Most
* operations entail locating an element (or position to insert an
* element). The code to do this can't be nicely factored out
* because subsequent uses require a snapshot of predecessor
* and/or successor and/or value fields which can't be returned
* all at once, at least not without creating yet another object
* to hold them -- creating such little objects is an especially
* bad idea for basic internal search operations because it adds
* to GC overhead. (This is one of the few times I've wished Java
* had macros.) Instead, some traversal code is interleaved within
* insertion and removal operations. The control logic to handle
* all the retry conditions is sometimes twisty. Most search is
* broken into 2 parts. findPredecessor() searches index nodes
* only, returning a base-level predecessor of the key. findNode()
* finishes out the base-level search. Even with this factoring,
* there is a fair amount of near-duplication of code to handle
* variants.
*
* For explanation of algorithms sharing at least a couple of
* features with this one, see Mikhail Fomitchev's thesis
* (http://www.cs.yorku.ca/~mikhail/), Keir Fraser's thesis
* (http://www.cl.cam.ac.uk/users/kaf24/), and Hakan Sundell's
* thesis (http://www.cs.chalmers.se/~phs/).
*
* Given the use of tree-like index nodes, you might wonder why
* this doesn't use some kind of search tree instead, which would
* support somewhat faster search operations. The reason is that
* there are no known efficient lock-free insertion and deletion
* algorithms for search trees. The immutability of the "down"
* links of index nodes (as opposed to mutable "left" fields in
* true trees) makes this tractable using only CAS operations.
*
* Notation guide for local variables
* Node: b, n, f for predecessor, node, successor
* Index: q, r, d for index node, right, down.
* t for another index node
* Head: h
* Levels: j
* Keys: k, key
* Values: v, value
* Comparisons: c
*/
private static final long serialVersionUID = -8627078645895051609L;
/**
* Generates the initial random seed for the cheaper per-instance
* random number generators used in randomLevel.
*/
private static final Random seedGenerator = new Random();
/**
* Special value used to identify base-level header
*/
private static final Object BASE_HEADER = new Object();
/**
* The topmost head index of the skiplist.
*/
private transient volatile HeadIndex<K,V> head;
/**
* The comparator used to maintain order in this map, or null
* if using natural ordering.
* @serial
*/
private final Comparator<? super K> comparator;
/**
* Seed for simple random number generator. Not volatile since it
* doesn't matter too much if different threads don't see updates.
*/
private transient int randomSeed;
/** Lazily initialized key set */
private transient KeySet keySet;
/** Lazily initialized entry set */
private transient EntrySet entrySet;
/** Lazily initialized values collection */
private transient Values values;
/** Lazily initialized descending key set */
private transient ConcurrentNavigableMap<K,V> descendingMap;
/**
* Initializes or resets state. Needed by constructors, clone,
* clear, readObject. and ConcurrentSkipListSet.clone.
* (Note that comparator must be separately initialized.)
*/
final void initialize() {
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
randomSeed = seedGenerator.nextInt() | 0x0100; // ensure nonzero
head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null),
null, null, 1);
}
/**
* compareAndSet head node
*/
private boolean casHead(HeadIndex<K,V> cmp, HeadIndex<K,V> val) {
return UNSAFE.compareAndSwapObject(this, headOffset, cmp, val);
}
/* ---------------- Nodes -------------- */
/**
* Nodes hold keys and values, and are singly linked in sorted
* order, possibly with some intervening marker nodes. The list is
* headed by a dummy node accessible as head.node. The value field
* is declared only as Object because it takes special non-V
* values for marker and header nodes.
*/
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
/**
* Creates a new regular node.
*/
Node(K key, Object value, Node<K,V> next) {
this.key = key;
this.value = value;
this.next = next;
}
/**
* Creates a new marker node. A marker is distinguished by
* having its value field point to itself. Marker nodes also
* have null keys, a fact that is exploited in a few places,
* but this doesn't distinguish markers from the base-level
* header node (head.node), which also has a null key.
*/
Node(Node<K,V> next) {
this.key = null;
this.value = this;
this.next = next;
}
/**
* compareAndSet value field
*/
boolean casValue(Object cmp, Object val) {
return UNSAFE.compareAndSwapObject(this, valueOffset, cmp, val);
}
/**
* compareAndSet next field
*/
boolean casNext(Node<K,V> cmp, Node<K,V> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
/**
* Returns true if this node is a marker. This method isn't
* actually called in any current code checking for markers
* because callers will have already read value field and need
* to use that read (not another done here) and so directly
* test if value points to node.
* @param n a possibly null reference to a node
* @return true if this node is a marker node
*/
boolean isMarker() {
return value == this;
}
/**
* Returns true if this node is the header of base-level list.
* @return true if this node is header node
*/
boolean isBaseHeader() {
return value == BASE_HEADER;
}
/**
* Tries to append a deletion marker to this node.
* @param f the assumed current successor of this node
* @return true if successful
*/
boolean appendMarker(Node<K,V> f) {
return casNext(f, new Node<K,V>(f));
}
/**
* Helps out a deletion by appending marker or unlinking from
* predecessor. This is called during traversals when value
* field seen to be null.
* @param b predecessor
* @param f successor
*/
void helpDelete(Node<K,V> b, Node<K,V> f) {
/*
* Rechecking links and then doing only one of the
* help-out stages per call tends to minimize CAS
* interference among helping threads.
*/
if (f == next && this == b.next) {
if (f == null || f.value != f) // not already marked
appendMarker(f);
else
b.casNext(this, f.next);
}
}
/**
* Returns value if this node contains a valid key-value pair,
* else null.
* @return this node's value if it isn't a marker or header or
* is deleted, else null.
*/
V getValidValue() {
Object v = value;
if (v == this || v == BASE_HEADER)
return null;
return (V)v;
}
/**
* Creates and returns a new SimpleImmutableEntry holding current
* mapping if this node holds a valid value, else null.
* @return new entry or null
*/
AbstractMap.SimpleImmutableEntry<K,V> createSnapshot() {
V v = getValidValue();
if (v == null)
return null;
return new AbstractMap.SimpleImmutableEntry<K,V>(key, v);
}
// UNSAFE mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = Node.class;
valueOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("value"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
/* ---------------- Indexing -------------- */
/**
* Index nodes represent the levels of the skip list. Note that
* even though both Nodes and Indexes have forward-pointing
* fields, they have different types and are handled in different
* ways, that can't nicely be captured by placing field in a
* shared abstract class.
*/
static class Index<K,V> {
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
/**
* Creates index node with given values.
*/
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
/**
* compareAndSet right field
*/
final boolean casRight(Index<K,V> cmp, Index<K,V> val) {
return UNSAFE.compareAndSwapObject(this, rightOffset, cmp, val);
}
/**
* Returns true if the node this indexes has been deleted.
* @return true if indexed node is known to be deleted
*/
final boolean indexesDeletedNode() {
return node.value == null;
}
/**
* Tries to CAS newSucc as successor. To minimize races with
* unlink that may lose this index node, if the node being
* indexed is known to be deleted, it doesn't try to link in.
* @param succ the expected current successor
* @param newSucc the new successor
* @return true if successful
*/
final boolean link(Index<K,V> succ, Index<K,V> newSucc) {
Node<K,V> n = node;
newSucc.right = succ;
return n.value != null && casRight(succ, newSucc);
}
/**
* Tries to CAS right field to skip over apparent successor
* succ. Fails (forcing a retraversal by caller) if this node
* is known to be deleted.
* @param succ the expected current successor
* @return true if successful
*/
final boolean unlink(Index<K,V> succ) {
return !indexesDeletedNode() && casRight(succ, succ.right);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long rightOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = Index.class;
rightOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("right"));
} catch (Exception e) {
throw new Error(e);
}
}
}
/* ---------------- Head nodes -------------- */
/**
* Nodes heading each level keep track of their level.
*/
static final class HeadIndex<K,V> extends Index<K,V> {
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
/* ---------------- Comparison utilities -------------- */
/**
* Represents a key with a comparator as a Comparable.
*
* Because most sorted collections seem to use natural ordering on
* Comparables (Strings, Integers, etc), most internal methods are
* geared to use them. This is generally faster than checking
* per-comparison whether to use comparator or comparable because
* it doesn't require a (Comparable) cast for each comparison.
* (Optimizers can only sometimes remove such redundant checks
* themselves.) When Comparators are used,
* ComparableUsingComparators are created so that they act in the
* same way as natural orderings. This penalizes use of
* Comparators vs Comparables, which seems like the right
* tradeoff.
*/
static final class ComparableUsingComparator<K> implements Comparable<K> {
final K actualKey;
final Comparator<? super K> cmp;
ComparableUsingComparator(K key, Comparator<? super K> cmp) {
this.actualKey = key;
this.cmp = cmp;
}
public int compareTo(K k2) {
return cmp.compare(actualKey, k2);
}
}
/**
* If using comparator, return a ComparableUsingComparator, else
* cast key as Comparable, which may cause ClassCastException,
* which is propagated back to caller.
*/
private Comparable<? super K> comparable(Object key)
throws ClassCastException {
if (key == null)
throw new NullPointerException();
if (comparator != null)
return new ComparableUsingComparator<K>((K)key, comparator);
else
return (Comparable<? super K>)key;
}
/**
* Compares using comparator or natural ordering. Used when the
* ComparableUsingComparator approach doesn't apply.
*/
int compare(K k1, K k2) throws ClassCastException {
Comparator<? super K> cmp = comparator;
if (cmp != null)
return cmp.compare(k1, k2);
else
return ((Comparable<? super K>)k1).compareTo(k2);
}
/**
* Returns true if given key greater than or equal to least and
* strictly less than fence, bypassing either test if least or
* fence are null. Needed mainly in submap operations.
*/
boolean inHalfOpenRange(K key, K least, K fence) {
if (key == null)
throw new NullPointerException();
return ((least == null || compare(key, least) >= 0) &&
(fence == null || compare(key, fence) < 0));
}
/**
* Returns true if given key greater than or equal to least and less
* or equal to fence. Needed mainly in submap operations.
*/
boolean inOpenRange(K key, K least, K fence) {
if (key == null)
throw new NullPointerException();
return ((least == null || compare(key, least) >= 0) &&
(fence == null || compare(key, fence) <= 0));
}
/* ---------------- Traversal -------------- */
/**
* Returns a base-level node with key strictly less than given key,
* or the base-level header if there is no such node. Also
* unlinks indexes to deleted nodes found along the way. Callers
* rely on this side-effect of clearing indices to deleted nodes.
* @param key the key
* @return a predecessor of key
*/
private Node<K,V> findPredecessor(Comparable<? super K> key) {
if (key == null)
throw new NullPointerException(); // don't postpone errors
for (;;) {
Index<K,V> q = head;
Index<K,V> r = q.right;
for (;;) {
if (r != null) {
Node<K,V> n = r.node;
K k = n.key;
if (n.value == null) {
if (!q.unlink(r))
break; // restart
r = q.right; // reread r
continue;
}
if (key.compareTo(k) > 0) {
q = r;
r = r.right;
continue;
}
}
Index<K,V> d = q.down;
if (d != null) {
q = d;
r = d.right;
} else
return q.node;
}
}
}
/**
* Returns node holding key or null if no such, clearing out any
* deleted nodes seen along the way. Repeatedly traverses at
* base-level looking for key starting at predecessor returned
* from findPredecessor, processing base-level deletions as
* encountered. Some callers rely on this side-effect of clearing
* deleted nodes.
*
* Restarts occur, at traversal step centered on node n, if:
*
* (1) After reading n's next field, n is no longer assumed
* predecessor b's current successor, which means that
* we don't have a consistent 3-node snapshot and so cannot
* unlink any subsequent deleted nodes encountered.
*
* (2) n's value field is null, indicating n is deleted, in
* which case we help out an ongoing structural deletion
* before retrying. Even though there are cases where such
* unlinking doesn't require restart, they aren't sorted out
* here because doing so would not usually outweigh cost of
* restarting.
*
* (3) n is a marker or n's predecessor's value field is null,
* indicating (among other possibilities) that
* findPredecessor returned a deleted node. We can't unlink
* the node because we don't know its predecessor, so rely
* on another call to findPredecessor to notice and return
* some earlier predecessor, which it will do. This check is
* only strictly needed at beginning of loop, (and the
* b.value check isn't strictly needed at all) but is done
* each iteration to help avoid contention with other
* threads by callers that will fail to be able to change
* links, and so will retry anyway.
*
* The traversal loops in doPut, doRemove, and findNear all
* include the same three kinds of checks. And specialized
* versions appear in findFirst, and findLast and their
* variants. They can't easily share code because each uses the
* reads of fields held in locals occurring in the orders they
* were performed.
*
* @param key the key
* @return node holding key, or null if no such
*/
private Node<K,V> findNode(Comparable<? super K> key) {
for (;;) {
Node<K,V> b = findPredecessor(key);
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return null;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c == 0)
return n;
if (c < 0)
return null;
b = n;
n = f;
}
}
}
/**
* Gets value for key using findNode.
* @param okey the key
* @return the value, or null if absent
*/
private V doGet(Object okey) {
Comparable<? super K> key = comparable(okey);
/*
* Loop needed here and elsewhere in case value field goes
* null just as it is about to be returned, in which case we
* lost a race with a deletion, so must retry.
*/
for (;;) {
Node<K,V> n = findNode(key);
if (n == null)
return null;
Object v = n.value;
if (v != null)
return (V)v;
}
}
/* ---------------- Insertion -------------- */
/**
* Main insertion method. Adds element if not present, or
* replaces value if present and onlyIfAbsent is false.
* @param kkey the key
* @param value the value that must be associated with key
* @param onlyIfAbsent if should not insert if already present
* @return the old value, or null if newly inserted
*/
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
Node<K,V> b = findPredecessor(key);
Node<K,V> n = b.next;
for (;;) {
if (n != null) {
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c > 0) {
b = n;
n = f;
continue;
}
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
Node<K,V> z = new Node<K,V>(kkey, value, n);
if (!b.casNext(n, z))
break; // restart if lost race to append to b
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
/**
* Returns a random level for inserting a new node.
* Hardwired to k=1, p=0.5, max 31 (see above and
* Pugh's "Skip List Cookbook", sec 3.4).
*
* This uses the simplest of the generators described in George
* Marsaglia's "Xorshift RNGs" paper. This is not a high-quality
* generator but is acceptable here.
*/
private int randomLevel() {
int x = randomSeed;
x ^= x << 13;
x ^= x >>> 17;
randomSeed = x ^= x << 5;
if ((x & 0x80000001) != 0) // test highest and lowest bits
return 0;
int level = 1;
while (((x >>>= 1) & 1) != 0) ++level;
return level;
}
/**
* Creates and adds index nodes for the given node.
* @param z the node
* @param level the level of the index
*/
private void insertIndex(Node<K,V> z, int level) {
HeadIndex<K,V> h = head;
int max = h.level;
if (level <= max) {
Index<K,V> idx = null;
for (int i = 1; i <= level; ++i)
idx = new Index<K,V>(z, idx, null);
addIndex(idx, h, level);
} else { // Add a new level
/*
* To reduce interference by other threads checking for
* empty levels in tryReduceLevel, new levels are added
* with initialized right pointers. Which in turn requires
* keeping levels in an array to access them while
* creating new head index nodes from the opposite
* direction.
*/
level = max + 1;
Index<K,V>[] idxs = (Index<K,V>[])new Index[level+1];
Index<K,V> idx = null;
for (int i = 1; i <= level; ++i)
idxs[i] = idx = new Index<K,V>(z, idx, null);
HeadIndex<K,V> oldh;
int k;
for (;;) {
oldh = head;
int oldLevel = oldh.level;
if (level <= oldLevel) { // lost race to add level
k = level;
break;
}
HeadIndex<K,V> newh = oldh;
Node<K,V> oldbase = oldh.node;
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
if (casHead(oldh, newh)) {
k = oldLevel;
break;
}
}
addIndex(idxs[k], oldh, k);
}
}
/**
* Adds given index nodes from given level down to 1.
* @param idx the topmost index node being inserted
* @param h the value of head to use to insert. This must be
* snapshotted by callers to provide correct insertion level
* @param indexLevel the level of the index
*/
private void addIndex(Index<K,V> idx, HeadIndex<K,V> h, int indexLevel) {
// Track next level to insert in case of retries
int insertionLevel = indexLevel;
Comparable<? super K> key = comparable(idx.node.key);
if (key == null) throw new NullPointerException();
// Similar to findPredecessor, but adding index nodes along
// path to key.
for (;;) {
int j = h.level;
Index<K,V> q = h;
Index<K,V> r = q.right;
Index<K,V> t = idx;
for (;;) {
if (r != null) {
Node<K,V> n = r.node;
// compare before deletion check avoids needing recheck
int c = key.compareTo(n.key);
if (n.value == null) {
if (!q.unlink(r))
break;
r = q.right;
continue;
}
if (c > 0) {
q = r;
r = r.right;
continue;
}
}
if (j == insertionLevel) {
// Don't insert index if node already deleted
if (t.indexesDeletedNode()) {
findNode(key); // cleans up
return;
}
if (!q.link(r, t))
break; // restart
if (--insertionLevel == 0) {
// need final deletion check before return
if (t.indexesDeletedNode())
findNode(key);
return;
}
}
if (--j >= insertionLevel && j < indexLevel)
t = t.down;
q = q.down;
r = q.right;
}
}
}
/* ---------------- Deletion -------------- */
/**
* Main deletion method. Locates node, nulls value, appends a
* deletion marker, unlinks predecessor, removes associated index
* nodes, and possibly reduces head index level.
*
* Index nodes are cleared out simply by calling findPredecessor.
* which unlinks indexes to deleted nodes found along path to key,
* which will include the indexes to this node. This is done
* unconditionally. We can't check beforehand whether there are
* index nodes because it might be the case that some or all
* indexes hadn't been inserted yet for this node during initial
* search for it, and we'd like to ensure lack of garbage
* retention, so must call to be sure.
*
* @param okey the key
* @param value if non-null, the value that must be
* associated with key
* @return the node, or null if not found
*/
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
Node<K,V> b = findPredecessor(key);
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return null;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c < 0)
return null;
if (c > 0) {
b = n;
n = f;
continue;
}
if (value != null && !value.equals(v))
return null;
if (!n.casValue(v, null))
break;
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // Retry via findNode
else {
findPredecessor(key); // Clean index
if (head.right == null)
tryReduceLevel();
}
return (V)v;
}
}
}
/**
* Possibly reduce head level if it has no nodes. This method can
* (rarely) make mistakes, in which case levels can disappear even
* though they are about to contain index nodes. This impacts
* performance, not correctness. To minimize mistakes as well as
* to reduce hysteresis, the level is reduced by one only if the
* topmost three levels look empty. Also, if the removed level
* looks non-empty after CAS, we try to change it back quick
* before anyone notices our mistake! (This trick works pretty
* well because this method will practically never make mistakes
* unless current thread stalls immediately before first CAS, in
* which case it is very unlikely to stall again immediately
* afterwards, so will recover.)
*
* We put up with all this rather than just let levels grow
* because otherwise, even a small map that has undergone a large
* number of insertions and removals will have a lot of levels,
* slowing down access more than would an occasional unwanted
* reduction.
*/
private void tryReduceLevel() {
HeadIndex<K,V> h = head;
HeadIndex<K,V> d;
HeadIndex<K,V> e;
if (h.level > 3 &&
(d = (HeadIndex<K,V>)h.down) != null &&
(e = (HeadIndex<K,V>)d.down) != null &&
e.right == null &&
d.right == null &&
h.right == null &&
casHead(h, d) && // try to set
h.right != null) // recheck
casHead(d, h); // try to backout
}
/* ---------------- Finding and removing first element -------------- */
/**
* Specialized variant of findNode to get first valid node.
* @return first node or null if empty
*/
Node<K,V> findFirst() {
for (;;) {
Node<K,V> b = head.node;
Node<K,V> n = b.next;
if (n == null)
return null;
if (n.value != null)
return n;
n.helpDelete(b, n.next);
}
}
/**
* Removes first entry; returns its snapshot.
* @return null if empty, else snapshot of first entry
*/
Map.Entry<K,V> doRemoveFirstEntry() {
for (;;) {
Node<K,V> b = head.node;
Node<K,V> n = b.next;
if (n == null)
return null;
Node<K,V> f = n.next;
if (n != b.next)
continue;
Object v = n.value;
if (v == null) {
n.helpDelete(b, f);
continue;
}
if (!n.casValue(v, null))
continue;
if (!n.appendMarker(f) || !b.casNext(n, f))
findFirst(); // retry
clearIndexToFirst();
return new AbstractMap.SimpleImmutableEntry<K,V>(n.key, (V)v);
}
}
/**
* Clears out index nodes associated with deleted first entry.
*/
private void clearIndexToFirst() {
for (;;) {
Index<K,V> q = head;
for (;;) {
Index<K,V> r = q.right;
if (r != null && r.indexesDeletedNode() && !q.unlink(r))
break;
if ((q = q.down) == null) {
if (head.right == null)
tryReduceLevel();
return;
}
}
}
}
/* ---------------- Finding and removing last element -------------- */
/**
* Specialized version of find to get last valid node.
* @return last node or null if empty
*/
Node<K,V> findLast() {
/*
* findPredecessor can't be used to traverse index level
* because this doesn't use comparisons. So traversals of
* both levels are folded together.
*/
Index<K,V> q = head;
for (;;) {
Index<K,V> d, r;
if ((r = q.right) != null) {
if (r.indexesDeletedNode()) {
q.unlink(r);
q = head; // restart
}
else
q = r;
} else if ((d = q.down) != null) {
q = d;
} else {
Node<K,V> b = q.node;
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return b.isBaseHeader() ? null : b;
Node<K,V> f = n.next; // inconsistent read
if (n != b.next)
break;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
b = n;
n = f;
}
q = head; // restart
}
}
}
/**
* Specialized variant of findPredecessor to get predecessor of last
* valid node. Needed when removing the last entry. It is possible
* that all successors of returned node will have been deleted upon
* return, in which case this method can be retried.
* @return likely predecessor of last node
*/
private Node<K,V> findPredecessorOfLast() {
for (;;) {
Index<K,V> q = head;
for (;;) {
Index<K,V> d, r;
if ((r = q.right) != null) {
if (r.indexesDeletedNode()) {
q.unlink(r);
break; // must restart
}
// proceed as far across as possible without overshooting
if (r.node.next != null) {
q = r;
continue;
}
}
if ((d = q.down) != null)
q = d;
else
return q.node;
}
}
}
/**
* Removes last entry; returns its snapshot.
* Specialized variant of doRemove.
* @return null if empty, else snapshot of last entry
*/
Map.Entry<K,V> doRemoveLastEntry() {
for (;;) {
Node<K,V> b = findPredecessorOfLast();
Node<K,V> n = b.next;
if (n == null) {
if (b.isBaseHeader()) // empty
return null;
else
continue; // all b's successors are deleted; retry
}
for (;;) {
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
if (f != null) {
b = n;
n = f;
continue;
}
if (!n.casValue(v, null))
break;
K key = n.key;
Comparable<? super K> ck = comparable(key);
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(ck); // Retry via findNode
else {
findPredecessor(ck); // Clean index
if (head.right == null)
tryReduceLevel();
}
return new AbstractMap.SimpleImmutableEntry<K,V>(key, (V)v);
}
}
}
/* ---------------- Relational operations -------------- */
// Control values OR'ed as arguments to findNear
private static final int EQ = 1;
private static final int LT = 2;
private static final int GT = 0; // Actually checked as !LT
/**
* Utility for ceiling, floor, lower, higher methods.
* @param kkey the key
* @param rel the relation -- OR'ed combination of EQ, LT, GT
* @return nearest node fitting relation, or null if no such
*/
Node<K,V> findNear(K kkey, int rel) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
Node<K,V> b = findPredecessor(key);
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return ((rel & LT) == 0 || b.isBaseHeader()) ? null : b;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if ((c == 0 && (rel & EQ) != 0) ||
(c < 0 && (rel & LT) == 0))
return n;
if ( c <= 0 && (rel & LT) != 0)
return b.isBaseHeader() ? null : b;
b = n;
n = f;
}
}
}
/**
* Returns SimpleImmutableEntry for results of findNear.
* @param key the key
* @param rel the relation -- OR'ed combination of EQ, LT, GT
* @return Entry fitting relation, or null if no such
*/
AbstractMap.SimpleImmutableEntry<K,V> getNear(K key, int rel) {
for (;;) {
Node<K,V> n = findNear(key, rel);
if (n == null)
return null;
AbstractMap.SimpleImmutableEntry<K,V> e = n.createSnapshot();
if (e != null)
return e;
}
}
/* ---------------- Constructors -------------- */
/**
* Constructs a new, empty map, sorted according to the
* {@linkplain Comparable natural ordering} of the keys.
*/
public ConcurrentSkipListMap() {
this.comparator = null;
initialize();
}
/**
* Constructs a new, empty map, sorted according to the specified
* comparator.
*
* @param comparator the comparator that will be used to order this map.
* If <tt>null</tt>, the {@linkplain Comparable natural
* ordering} of the keys will be used.
*/
public ConcurrentSkipListMap(Comparator<? super K> comparator) {
this.comparator = comparator;
initialize();
}
/**
* Constructs a new map containing the same mappings as the given map,
* sorted according to the {@linkplain Comparable natural ordering} of
* the keys.
*
* @param m the map whose mappings are to be placed in this map
* @throws ClassCastException if the keys in <tt>m</tt> are not
* {@link Comparable}, or are not mutually comparable
* @throws NullPointerException if the specified map or any of its keys
* or values are null
*/
public ConcurrentSkipListMap(Map<? extends K, ? extends V> m) {
this.comparator = null;
initialize();
putAll(m);
}
/**
* Constructs a new map containing the same mappings and using the
* same ordering as the specified sorted map.
*
* @param m the sorted map whose mappings are to be placed in this
* map, and whose comparator is to be used to sort this map
* @throws NullPointerException if the specified sorted map or any of
* its keys or values are null
*/
public ConcurrentSkipListMap(SortedMap<K, ? extends V> m) {
this.comparator = m.comparator();
initialize();
buildFromSorted(m);
}
/**
* Returns a shallow copy of this <tt>ConcurrentSkipListMap</tt>
* instance. (The keys and values themselves are not cloned.)
*
* @return a shallow copy of this map
*/
public ConcurrentSkipListMap<K,V> clone() {
ConcurrentSkipListMap<K,V> clone = null;
try {
clone = (ConcurrentSkipListMap<K,V>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.initialize();
clone.buildFromSorted(this);
return clone;
}
/**
* Streamlined bulk insertion to initialize from elements of
* given sorted map. Call only from constructor or clone
* method.
*/
private void buildFromSorted(SortedMap<K, ? extends V> map) {
if (map == null)
throw new NullPointerException();
HeadIndex<K,V> h = head;
Node<K,V> basepred = h.node;
// Track the current rightmost node at each level. Uses an
// ArrayList to avoid committing to initial or maximum level.
ArrayList<Index<K,V>> preds = new ArrayList<Index<K,V>>();
// initialize
for (int i = 0; i <= h.level; ++i)
preds.add(null);
Index<K,V> q = h;
for (int i = h.level; i > 0; --i) {
preds.set(i, q);
q = q.down;
}
Iterator<? extends Map.Entry<? extends K, ? extends V>> it =
map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<? extends K, ? extends V> e = it.next();
int j = randomLevel();
if (j > h.level) j = h.level + 1;
K k = e.getKey();
V v = e.getValue();
if (k == null || v == null)
throw new NullPointerException();
Node<K,V> z = new Node<K,V>(k, v, null);
basepred.next = z;
basepred = z;
if (j > 0) {
Index<K,V> idx = null;
for (int i = 1; i <= j; ++i) {
idx = new Index<K,V>(z, idx, null);
if (i > h.level)
h = new HeadIndex<K,V>(h.node, h, idx, i);
if (i < preds.size()) {
preds.get(i).right = idx;
preds.set(i, idx);
} else
preds.add(idx);
}
}
}
head = h;
}
/* ---------------- Serialization -------------- */
/**
* Save the state of this map to a stream.
*
* @serialData The key (Object) and value (Object) for each
* key-value mapping represented by the map, followed by
* <tt>null</tt>. The key-value mappings are emitted in key-order
* (as determined by the Comparator, or by the keys' natural
* ordering if no Comparator).
*/
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// Write out the Comparator and any hidden stuff
s.defaultWriteObject();
// Write out keys and values (alternating)
for (Node<K,V> n = findFirst(); n != null; n = n.next) {
V v = n.getValidValue();
if (v != null) {
s.writeObject(n.key);
s.writeObject(v);
}
}
s.writeObject(null);
}
/**
* Reconstitute the map from a stream.
*/
private void readObject(final java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
// Read in the Comparator and any hidden stuff
s.defaultReadObject();
// Reset transients
initialize();
/*
* This is nearly identical to buildFromSorted, but is
* distinct because readObject calls can't be nicely adapted
* as the kind of iterator needed by buildFromSorted. (They
* can be, but doing so requires type cheats and/or creation
* of adaptor classes.) It is simpler to just adapt the code.
*/
HeadIndex<K,V> h = head;
Node<K,V> basepred = h.node;
ArrayList<Index<K,V>> preds = new ArrayList<Index<K,V>>();
for (int i = 0; i <= h.level; ++i)
preds.add(null);
Index<K,V> q = h;
for (int i = h.level; i > 0; --i) {
preds.set(i, q);
q = q.down;
}
for (;;) {
Object k = s.readObject();
if (k == null)
break;
Object v = s.readObject();
if (v == null)
throw new NullPointerException();
K key = (K) k;
V val = (V) v;
int j = randomLevel();
if (j > h.level) j = h.level + 1;
Node<K,V> z = new Node<K,V>(key, val, null);
basepred.next = z;
basepred = z;
if (j > 0) {
Index<K,V> idx = null;
for (int i = 1; i <= j; ++i) {
idx = new Index<K,V>(z, idx, null);
if (i > h.level)
h = new HeadIndex<K,V>(h.node, h, idx, i);
if (i < preds.size()) {
preds.get(i).right = idx;
preds.set(i, idx);
} else
preds.add(idx);
}
}
}
head = h;
}
/* ------ Map API methods ------ */
/**
* Returns <tt>true</tt> if this map contains a mapping for the specified
* key.
*
* @param key key whose presence in this map is to be tested
* @return <tt>true</tt> if this map contains a mapping for the specified key
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key is null
*/
public boolean containsKey(Object key) {
return doGet(key) != null;
}
/**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code key} compares
* equal to {@code k} according to the map's ordering, then this
* method returns {@code v}; otherwise it returns {@code null}.
* (There can be at most one such mapping.)
*
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key is null
*/
public V get(Object key) {
return doGet(key);
}
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with the specified key, or
* <tt>null</tt> if there was no mapping for the key
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key or value is null
*/
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
/**
* Removes the mapping for the specified key from this map if present.
*
* @param key key for which mapping should be removed
* @return the previous value associated with the specified key, or
* <tt>null</tt> if there was no mapping for the key
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key is null
*/
public V remove(Object key) {
return doRemove(key, null);
}
/**
* Returns <tt>true</tt> if this map maps one or more keys to the
* specified value. This operation requires time linear in the
* map size. Additionally, it is possible for the map to change
* during execution of this method, in which case the returned
* result may be inaccurate.
*
* @param value value whose presence in this map is to be tested
* @return <tt>true</tt> if a mapping to <tt>value</tt> exists;
* <tt>false</tt> otherwise
* @throws NullPointerException if the specified value is null
*/
public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
for (Node<K,V> n = findFirst(); n != null; n = n.next) {
V v = n.getValidValue();
if (v != null && value.equals(v))
return true;
}
return false;
}
/**
* Returns the number of key-value mappings in this map. If this map
* contains more than <tt>Integer.MAX_VALUE</tt> elements, it
* returns <tt>Integer.MAX_VALUE</tt>.
*
* <p>Beware that, unlike in most collections, this method is
* <em>NOT</em> a constant-time operation. Because of the
* asynchronous nature of these maps, determining the current
* number of elements requires traversing them all to count them.
* Additionally, it is possible for the size to change during
* execution of this method, in which case the returned result
* will be inaccurate. Thus, this method is typically not very
* useful in concurrent applications.
*
* @return the number of elements in this map
*/
public int size() {
long count = 0;
for (Node<K,V> n = findFirst(); n != null; n = n.next) {
if (n.getValidValue() != null)
++count;
}
return (count >= Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) count;
}
/**
* Returns <tt>true</tt> if this map contains no key-value mappings.
* @return <tt>true</tt> if this map contains no key-value mappings
*/
public boolean isEmpty() {
return findFirst() == null;
}
/**
* Removes all of the mappings from this map.
*/
public void clear() {
initialize();
}
/* ---------------- View methods -------------- */
/*
* Note: Lazy initialization works for views because view classes
* are stateless/immutable so it doesn't matter wrt correctness if
* more than one is created (which will only rarely happen). Even
* so, the following idiom conservatively ensures that the method
* returns the one it created if it does so, not one created by
* another racing thread.
*/
/**
* Returns a {@link NavigableSet} view of the keys contained in this map.
* The set's iterator returns the keys in ascending order.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. The set supports element
* removal, which removes the corresponding mapping from the map,
* via the {@code Iterator.remove}, {@code Set.remove},
* {@code removeAll}, {@code retainAll}, and {@code clear}
* operations. It does not support the {@code add} or {@code addAll}
* operations.
*
* <p>The view's {@code iterator} is a "weakly consistent" iterator
* that will never throw {@link ConcurrentModificationException},
* and guarantees to traverse elements as they existed upon
* construction of the iterator, and may (but is not guaranteed to)
* reflect any modifications subsequent to construction.
*
* <p>This method is equivalent to method {@code navigableKeySet}.
*
* @return a navigable set view of the keys in this map
*/
public NavigableSet<K> keySet() {
KeySet ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet(this));
}
public NavigableSet<K> navigableKeySet() {
KeySet ks = keySet;
return (ks != null) ? ks : (keySet = new KeySet(this));
}
/**
* Returns a {@link Collection} view of the values contained in this map.
* The collection's iterator returns the values in ascending order
* of the corresponding keys.
* The collection is backed by the map, so changes to the map are
* reflected in the collection, and vice-versa. The collection
* supports element removal, which removes the corresponding
* mapping from the map, via the <tt>Iterator.remove</tt>,
* <tt>Collection.remove</tt>, <tt>removeAll</tt>,
* <tt>retainAll</tt> and <tt>clear</tt> operations. It does not
* support the <tt>add</tt> or <tt>addAll</tt> operations.
*
* <p>The view's <tt>iterator</tt> is a "weakly consistent" iterator
* that will never throw {@link ConcurrentModificationException},
* and guarantees to traverse elements as they existed upon
* construction of the iterator, and may (but is not guaranteed to)
* reflect any modifications subsequent to construction.
*/
public Collection<V> values() {
Values vs = values;
return (vs != null) ? vs : (values = new Values(this));
}
/**
* Returns a {@link Set} view of the mappings contained in this map.
* The set's iterator returns the entries in ascending key order.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. The set supports element
* removal, which removes the corresponding mapping from the map,
* via the <tt>Iterator.remove</tt>, <tt>Set.remove</tt>,
* <tt>removeAll</tt>, <tt>retainAll</tt> and <tt>clear</tt>
* operations. It does not support the <tt>add</tt> or
* <tt>addAll</tt> operations.
*
* <p>The view's <tt>iterator</tt> is a "weakly consistent" iterator
* that will never throw {@link ConcurrentModificationException},
* and guarantees to traverse elements as they existed upon
* construction of the iterator, and may (but is not guaranteed to)
* reflect any modifications subsequent to construction.
*
* <p>The <tt>Map.Entry</tt> elements returned by
* <tt>iterator.next()</tt> do <em>not</em> support the
* <tt>setValue</tt> operation.
*
* @return a set view of the mappings contained in this map,
* sorted in ascending key order
*/
public Set<Map.Entry<K,V>> entrySet() {
EntrySet es = entrySet;
return (es != null) ? es : (entrySet = new EntrySet(this));
}
public ConcurrentNavigableMap<K,V> descendingMap() {
ConcurrentNavigableMap<K,V> dm = descendingMap;
return (dm != null) ? dm : (descendingMap = new SubMap<K,V>
(this, null, false, null, false, true));
}
public NavigableSet<K> descendingKeySet() {
return descendingMap().navigableKeySet();
}
/* ---------------- AbstractMap Overrides -------------- */
/**
* Compares the specified object with this map for equality.
* Returns <tt>true</tt> if the given object is also a map and the
* two maps represent the same mappings. More formally, two maps
* <tt>m1</tt> and <tt>m2</tt> represent the same mappings if
* <tt>m1.entrySet().equals(m2.entrySet())</tt>. This
* operation may return misleading results if either map is
* concurrently modified during execution of this method.
*
* @param o object to be compared for equality with this map
* @return <tt>true</tt> if the specified object is equal to this map
*/
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Map))
return false;
Map<?,?> m = (Map<?,?>) o;
try {
for (Map.Entry<K,V> e : this.entrySet())
if (! e.getValue().equals(m.get(e.getKey())))
return false;
for (Map.Entry<?,?> e : m.entrySet()) {
Object k = e.getKey();
Object v = e.getValue();
if (k == null || v == null || !v.equals(get(k)))
return false;
}
return true;
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
/* ------ ConcurrentMap API methods ------ */
/**
* {@inheritDoc}
*
* @return the previous value associated with the specified key,
* or <tt>null</tt> if there was no mapping for the key
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key or value is null
*/
public V putIfAbsent(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, true);
}
/**
* {@inheritDoc}
*
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key is null
*/
public boolean remove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
if (value == null)
return false;
return doRemove(key, value) != null;
}
/**
* {@inheritDoc}
*
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if any of the arguments are null
*/
public boolean replace(K key, V oldValue, V newValue) {
if (oldValue == null || newValue == null)
throw new NullPointerException();
Comparable<? super K> k = comparable(key);
for (;;) {
Node<K,V> n = findNode(k);
if (n == null)
return false;
Object v = n.value;
if (v != null) {
if (!oldValue.equals(v))
return false;
if (n.casValue(v, newValue))
return true;
}
}
}
/**
* {@inheritDoc}
*
* @return the previous value associated with the specified key,
* or <tt>null</tt> if there was no mapping for the key
* @throws ClassCastException if the specified key cannot be compared
* with the keys currently in the map
* @throws NullPointerException if the specified key or value is null
*/
public V replace(K key, V value) {
if (value == null)
throw new NullPointerException();
Comparable<? super K> k = comparable(key);
for (;;) {
Node<K,V> n = findNode(k);
if (n == null)
return null;
Object v = n.value;
if (v != null && n.casValue(v, value))
return (V)v;
}
}
/* ------ SortedMap API methods ------ */
public Comparator<? super K> comparator() {
return comparator;
}
/**
* @throws NoSuchElementException {@inheritDoc}
*/
public K firstKey() {
Node<K,V> n = findFirst();
if (n == null)
throw new NoSuchElementException();
return n.key;
}
/**
* @throws NoSuchElementException {@inheritDoc}
*/
public K lastKey() {
Node<K,V> n = findLast();
if (n == null)
throw new NoSuchElementException();
return n.key;
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if {@code fromKey} or {@code toKey} is null
* @throws IllegalArgumentException {@inheritDoc}
*/
public ConcurrentNavigableMap<K,V> subMap(K fromKey,
boolean fromInclusive,
K toKey,
boolean toInclusive) {
if (fromKey == null || toKey == null)
throw new NullPointerException();
return new SubMap<K,V>
(this, fromKey, fromInclusive, toKey, toInclusive, false);
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if {@code toKey} is null
* @throws IllegalArgumentException {@inheritDoc}
*/
public ConcurrentNavigableMap<K,V> headMap(K toKey,
boolean inclusive) {
if (toKey == null)
throw new NullPointerException();
return new SubMap<K,V>
(this, null, false, toKey, inclusive, false);
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if {@code fromKey} is null
* @throws IllegalArgumentException {@inheritDoc}
*/
public ConcurrentNavigableMap<K,V> tailMap(K fromKey,
boolean inclusive) {
if (fromKey == null)
throw new NullPointerException();
return new SubMap<K,V>
(this, fromKey, inclusive, null, false, false);
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if {@code fromKey} or {@code toKey} is null
* @throws IllegalArgumentException {@inheritDoc}
*/
public ConcurrentNavigableMap<K,V> subMap(K fromKey, K toKey) {
return subMap(fromKey, true, toKey, false);
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if {@code toKey} is null
* @throws IllegalArgumentException {@inheritDoc}
*/
public ConcurrentNavigableMap<K,V> headMap(K toKey) {
return headMap(toKey, false);
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if {@code fromKey} is null
* @throws IllegalArgumentException {@inheritDoc}
*/
public ConcurrentNavigableMap<K,V> tailMap(K fromKey) {
return tailMap(fromKey, true);
}
/* ---------------- Relational operations -------------- */
/**
* Returns a key-value mapping associated with the greatest key
* strictly less than the given key, or <tt>null</tt> if there is
* no such key. The returned entry does <em>not</em> support the
* <tt>Entry.setValue</tt> method.
*
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public Map.Entry<K,V> lowerEntry(K key) {
return getNear(key, LT);
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public K lowerKey(K key) {
Node<K,V> n = findNear(key, LT);
return (n == null) ? null : n.key;
}
/**
* Returns a key-value mapping associated with the greatest key
* less than or equal to the given key, or <tt>null</tt> if there
* is no such key. The returned entry does <em>not</em> support
* the <tt>Entry.setValue</tt> method.
*
* @param key the key
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public Map.Entry<K,V> floorEntry(K key) {
return getNear(key, LT|EQ);
}
/**
* @param key the key
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public K floorKey(K key) {
Node<K,V> n = findNear(key, LT|EQ);
return (n == null) ? null : n.key;
}
/**
* Returns a key-value mapping associated with the least key
* greater than or equal to the given key, or <tt>null</tt> if
* there is no such entry. The returned entry does <em>not</em>
* support the <tt>Entry.setValue</tt> method.
*
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public Map.Entry<K,V> ceilingEntry(K key) {
return getNear(key, GT|EQ);
}
/**
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public K ceilingKey(K key) {
Node<K,V> n = findNear(key, GT|EQ);
return (n == null) ? null : n.key;
}
/**
* Returns a key-value mapping associated with the least key
* strictly greater than the given key, or <tt>null</tt> if there
* is no such key. The returned entry does <em>not</em> support
* the <tt>Entry.setValue</tt> method.
*
* @param key the key
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public Map.Entry<K,V> higherEntry(K key) {
return getNear(key, GT);
}
/**
* @param key the key
* @throws ClassCastException {@inheritDoc}
* @throws NullPointerException if the specified key is null
*/
public K higherKey(K key) {
Node<K,V> n = findNear(key, GT);
return (n == null) ? null : n.key;
}
/**
* Returns a key-value mapping associated with the least
* key in this map, or <tt>null</tt> if the map is empty.
* The returned entry does <em>not</em> support
* the <tt>Entry.setValue</tt> method.
*/
public Map.Entry<K,V> firstEntry() {
for (;;) {
Node<K,V> n = findFirst();
if (n == null)
return null;
AbstractMap.SimpleImmutableEntry<K,V> e = n.createSnapshot();
if (e != null)
return e;
}
}
/**
* Returns a key-value mapping associated with the greatest
* key in this map, or <tt>null</tt> if the map is empty.
* The returned entry does <em>not</em> support
* the <tt>Entry.setValue</tt> method.
*/
public Map.Entry<K,V> lastEntry() {
for (;;) {
Node<K,V> n = findLast();
if (n == null)
return null;
AbstractMap.SimpleImmutableEntry<K,V> e = n.createSnapshot();
if (e != null)
return e;
}
}
/**
* Removes and returns a key-value mapping associated with
* the least key in this map, or <tt>null</tt> if the map is empty.
* The returned entry does <em>not</em> support
* the <tt>Entry.setValue</tt> method.
*/
public Map.Entry<K,V> pollFirstEntry() {
return doRemoveFirstEntry();
}
/**
* Removes and returns a key-value mapping associated with
* the greatest key in this map, or <tt>null</tt> if the map is empty.
* The returned entry does <em>not</em> support
* the <tt>Entry.setValue</tt> method.
*/
public Map.Entry<K,V> pollLastEntry() {
return doRemoveLastEntry();
}
/* ---------------- Iterators -------------- */
/**
* Base of iterator classes:
*/
abstract class Iter<T> implements Iterator<T> {
/** the last node returned by next() */
Node<K,V> lastReturned;
/** the next node to return from next(); */
Node<K,V> next;
/** Cache of next value field to maintain weak consistency */
V nextValue;
/** Initializes ascending iterator for entire range. */
Iter() {
for (;;) {
next = findFirst();
if (next == null)
break;
Object x = next.value;
if (x != null && x != next) {
nextValue = (V) x;
break;
}
}
}
public final boolean hasNext() {
return next != null;
}
/** Advances next to higher entry. */
final void advance() {
if (next == null)
throw new NoSuchElementException();
lastReturned = next;
for (;;) {
next = next.next;
if (next == null)
break;
Object x = next.value;
if (x != null && x != next) {
nextValue = (V) x;
break;
}
}
}
public void remove() {
Node<K,V> l = lastReturned;
if (l == null)
throw new IllegalStateException();
// It would not be worth all of the overhead to directly
// unlink from here. Using remove is fast enough.
ConcurrentSkipListMap.this.remove(l.key);
lastReturned = null;
}
}
final class ValueIterator extends Iter<V> {
public V next() {
V v = nextValue;
advance();
return v;
}
}
final class KeyIterator extends Iter<K> {
public K next() {
Node<K,V> n = next;
advance();
return n.key;
}
}
final class EntryIterator extends Iter<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
Node<K,V> n = next;
V v = nextValue;
advance();
return new AbstractMap.SimpleImmutableEntry<K,V>(n.key, v);
}
}
// Factory methods for iterators needed by ConcurrentSkipListSet etc
Iterator<K> keyIterator() {
return new KeyIterator();
}
Iterator<V> valueIterator() {
return new ValueIterator();
}
Iterator<Map.Entry<K,V>> entryIterator() {
return new EntryIterator();
}
/* ---------------- View Classes -------------- */
/*
* View classes are static, delegating to a ConcurrentNavigableMap
* to allow use by SubMaps, which outweighs the ugliness of
* needing type-tests for Iterator methods.
*/
static final <E> List<E> toList(Collection<E> c) {
// Using size() here would be a pessimization.
List<E> list = new ArrayList<E>();
for (E e : c)
list.add(e);
return list;
}
static final class KeySet<E>
extends AbstractSet<E> implements NavigableSet<E> {
private final ConcurrentNavigableMap<E,Object> m;
KeySet(ConcurrentNavigableMap<E,Object> map) { m = map; }
public int size() { return m.size(); }
public boolean isEmpty() { return m.isEmpty(); }
public boolean contains(Object o) { return m.containsKey(o); }
public boolean remove(Object o) { return m.remove(o) != null; }
public void clear() { m.clear(); }
public E lower(E e) { return m.lowerKey(e); }
public E floor(E e) { return m.floorKey(e); }
public E ceiling(E e) { return m.ceilingKey(e); }
public E higher(E e) { return m.higherKey(e); }
public Comparator<? super E> comparator() { return m.comparator(); }
public E first() { return m.firstKey(); }
public E last() { return m.lastKey(); }
public E pollFirst() {
Map.Entry<E,Object> e = m.pollFirstEntry();
return (e == null) ? null : e.getKey();
}
public E pollLast() {
Map.Entry<E,Object> e = m.pollLastEntry();
return (e == null) ? null : e.getKey();
}
public Iterator<E> iterator() {
if (m instanceof ConcurrentSkipListMap)
return ((ConcurrentSkipListMap<E,Object>)m).keyIterator();
else
return ((ConcurrentSkipListMap.SubMap<E,Object>)m).keyIterator();
}
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))
return false;
Collection<?> c = (Collection<?>) o;
try {
return containsAll(c) && c.containsAll(this);
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
public Object[] toArray() { return toList(this).toArray(); }
public <T> T[] toArray(T[] a) { return toList(this).toArray(a); }
public Iterator<E> descendingIterator() {
return descendingSet().iterator();
}
public NavigableSet<E> subSet(E fromElement,
boolean fromInclusive,
E toElement,
boolean toInclusive) {
return new KeySet<E>(m.subMap(fromElement, fromInclusive,
toElement, toInclusive));
}
public NavigableSet<E> headSet(E toElement, boolean inclusive) {
return new KeySet<E>(m.headMap(toElement, inclusive));
}
public NavigableSet<E> tailSet(E fromElement, boolean inclusive) {
return new KeySet<E>(m.tailMap(fromElement, inclusive));
}
public NavigableSet<E> subSet(E fromElement, E toElement) {
return subSet(fromElement, true, toElement, false);
}
public NavigableSet<E> headSet(E toElement) {
return headSet(toElement, false);
}
public NavigableSet<E> tailSet(E fromElement) {
return tailSet(fromElement, true);
}
public NavigableSet<E> descendingSet() {
return new KeySet(m.descendingMap());
}
}
static final class Values<E> extends AbstractCollection<E> {
private final ConcurrentNavigableMap<Object, E> m;
Values(ConcurrentNavigableMap<Object, E> map) {
m = map;
}
public Iterator<E> iterator() {
if (m instanceof ConcurrentSkipListMap)
return ((ConcurrentSkipListMap<Object,E>)m).valueIterator();
else
return ((SubMap<Object,E>)m).valueIterator();
}
public boolean isEmpty() {
return m.isEmpty();
}
public int size() {
return m.size();
}
public boolean contains(Object o) {
return m.containsValue(o);
}
public void clear() {
m.clear();
}
public Object[] toArray() { return toList(this).toArray(); }
public <T> T[] toArray(T[] a) { return toList(this).toArray(a); }
}
static final class EntrySet<K1,V1> extends AbstractSet<Map.Entry<K1,V1>> {
private final ConcurrentNavigableMap<K1, V1> m;
EntrySet(ConcurrentNavigableMap<K1, V1> map) {
m = map;
}
public Iterator<Map.Entry<K1,V1>> iterator() {
if (m instanceof ConcurrentSkipListMap)
return ((ConcurrentSkipListMap<K1,V1>)m).entryIterator();
else
return ((SubMap<K1,V1>)m).entryIterator();
}
public boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K1,V1> e = (Map.Entry<K1,V1>)o;
V1 v = m.get(e.getKey());
return v != null && v.equals(e.getValue());
}
public boolean remove(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<K1,V1> e = (Map.Entry<K1,V1>)o;
return m.remove(e.getKey(),
e.getValue());
}
public boolean isEmpty() {
return m.isEmpty();
}
public int size() {
return m.size();
}
public void clear() {
m.clear();
}
public boolean equals(Object o) {
if (o == this)
return true;
if (!(o instanceof Set))
return false;
Collection<?> c = (Collection<?>) o;
try {
return containsAll(c) && c.containsAll(this);
} catch (ClassCastException unused) {
return false;
} catch (NullPointerException unused) {
return false;
}
}
public Object[] toArray() { return toList(this).toArray(); }
public <T> T[] toArray(T[] a) { return toList(this).toArray(a); }
}
/**
* Submaps returned by {@link ConcurrentSkipListMap} submap operations
* represent a subrange of mappings of their underlying
* maps. Instances of this class support all methods of their
* underlying maps, differing in that mappings outside their range are
* ignored, and attempts to add mappings outside their ranges result
* in {@link IllegalArgumentException}. Instances of this class are
* constructed only using the <tt>subMap</tt>, <tt>headMap</tt>, and
* <tt>tailMap</tt> methods of their underlying maps.
*
* @serial include
*/
static final class SubMap<K,V> extends AbstractMap<K,V>
implements ConcurrentNavigableMap<K,V>, Cloneable,
java.io.Serializable {
private static final long serialVersionUID = -7647078645895051609L;
/** Underlying map */
private final ConcurrentSkipListMap<K,V> m;
/** lower bound key, or null if from start */
private final K lo;
/** upper bound key, or null if to end */
private final K hi;
/** inclusion flag for lo */
private final boolean loInclusive;
/** inclusion flag for hi */
private final boolean hiInclusive;
/** direction */
private final boolean isDescending;
// Lazily initialized view holders
private transient KeySet<K> keySetView;
private transient Set<Map.Entry<K,V>> entrySetView;
private transient Collection<V> valuesView;
/**
* Creates a new submap, initializing all fields
*/
SubMap(ConcurrentSkipListMap<K,V> map,
K fromKey, boolean fromInclusive,
K toKey, boolean toInclusive,
boolean isDescending) {
if (fromKey != null && toKey != null &&
map.compare(fromKey, toKey) > 0)
throw new IllegalArgumentException("inconsistent range");
this.m = map;
this.lo = fromKey;
this.hi = toKey;
this.loInclusive = fromInclusive;
this.hiInclusive = toInclusive;
this.isDescending = isDescending;
}
/* ---------------- Utilities -------------- */
private boolean tooLow(K key) {
if (lo != null) {
int c = m.compare(key, lo);
if (c < 0 || (c == 0 && !loInclusive))
return true;
}
return false;
}
private boolean tooHigh(K key) {
if (hi != null) {
int c = m.compare(key, hi);
if (c > 0 || (c == 0 && !hiInclusive))
return true;
}
return false;
}
private boolean inBounds(K key) {
return !tooLow(key) && !tooHigh(key);
}
private void checkKeyBounds(K key) throws IllegalArgumentException {
if (key == null)
throw new NullPointerException();
if (!inBounds(key))
throw new IllegalArgumentException("key out of range");
}
/**
* Returns true if node key is less than upper bound of range
*/
private boolean isBeforeEnd(ConcurrentSkipListMap.Node<K,V> n) {
if (n == null)
return false;
if (hi == null)
return true;
K k = n.key;
if (k == null) // pass by markers and headers
return true;
int c = m.compare(k, hi);
if (c > 0 || (c == 0 && !hiInclusive))
return false;
return true;
}
/**
* Returns lowest node. This node might not be in range, so
* most usages need to check bounds
*/
private ConcurrentSkipListMap.Node<K,V> loNode() {
if (lo == null)
return m.findFirst();
else if (loInclusive)
return m.findNear(lo, m.GT|m.EQ);
else
return m.findNear(lo, m.GT);
}
/**
* Returns highest node. This node might not be in range, so
* most usages need to check bounds
*/
private ConcurrentSkipListMap.Node<K,V> hiNode() {
if (hi == null)
return m.findLast();
else if (hiInclusive)
return m.findNear(hi, m.LT|m.EQ);
else
return m.findNear(hi, m.LT);
}
/**
* Returns lowest absolute key (ignoring directonality)
*/
private K lowestKey() {
ConcurrentSkipListMap.Node<K,V> n = loNode();
if (isBeforeEnd(n))
return n.key;
else
throw new NoSuchElementException();
}
/**
* Returns highest absolute key (ignoring directonality)
*/
private K highestKey() {
ConcurrentSkipListMap.Node<K,V> n = hiNode();
if (n != null) {
K last = n.key;
if (inBounds(last))
return last;
}
throw new NoSuchElementException();
}
private Map.Entry<K,V> lowestEntry() {
for (;;) {
ConcurrentSkipListMap.Node<K,V> n = loNode();
if (!isBeforeEnd(n))
return null;
Map.Entry<K,V> e = n.createSnapshot();
if (e != null)
return e;
}
}
private Map.Entry<K,V> highestEntry() {
for (;;) {
ConcurrentSkipListMap.Node<K,V> n = hiNode();
if (n == null || !inBounds(n.key))
return null;
Map.Entry<K,V> e = n.createSnapshot();
if (e != null)
return e;
}
}
private Map.Entry<K,V> removeLowest() {
for (;;) {
Node<K,V> n = loNode();
if (n == null)
return null;
K k = n.key;
if (!inBounds(k))
return null;
V v = m.doRemove(k, null);
if (v != null)
return new AbstractMap.SimpleImmutableEntry<K,V>(k, v);
}
}
private Map.Entry<K,V> removeHighest() {
for (;;) {
Node<K,V> n = hiNode();
if (n == null)
return null;
K k = n.key;
if (!inBounds(k))
return null;
V v = m.doRemove(k, null);
if (v != null)
return new AbstractMap.SimpleImmutableEntry<K,V>(k, v);
}
}
/**
* Submap version of ConcurrentSkipListMap.getNearEntry
*/
private Map.Entry<K,V> getNearEntry(K key, int rel) {
if (isDescending) { // adjust relation for direction
if ((rel & m.LT) == 0)
rel |= m.LT;
else
rel &= ~m.LT;
}
if (tooLow(key))
return ((rel & m.LT) != 0) ? null : lowestEntry();
if (tooHigh(key))
return ((rel & m.LT) != 0) ? highestEntry() : null;
for (;;) {
Node<K,V> n = m.findNear(key, rel);
if (n == null || !inBounds(n.key))
return null;
K k = n.key;
V v = n.getValidValue();
if (v != null)
return new AbstractMap.SimpleImmutableEntry<K,V>(k, v);
}
}
// Almost the same as getNearEntry, except for keys
private K getNearKey(K key, int rel) {
if (isDescending) { // adjust relation for direction
if ((rel & m.LT) == 0)
rel |= m.LT;
else
rel &= ~m.LT;
}
if (tooLow(key)) {
if ((rel & m.LT) == 0) {
ConcurrentSkipListMap.Node<K,V> n = loNode();
if (isBeforeEnd(n))
return n.key;
}
return null;
}
if (tooHigh(key)) {
if ((rel & m.LT) != 0) {
ConcurrentSkipListMap.Node<K,V> n = hiNode();
if (n != null) {
K last = n.key;
if (inBounds(last))
return last;
}
}
return null;
}
for (;;) {
Node<K,V> n = m.findNear(key, rel);
if (n == null || !inBounds(n.key))
return null;
K k = n.key;
V v = n.getValidValue();
if (v != null)
return k;
}
}
/* ---------------- Map API methods -------------- */
public boolean containsKey(Object key) {
if (key == null) throw new NullPointerException();
K k = (K)key;
return inBounds(k) && m.containsKey(k);
}
public V get(Object key) {
if (key == null) throw new NullPointerException();
K k = (K)key;
return ((!inBounds(k)) ? null : m.get(k));
}
public V put(K key, V value) {
checkKeyBounds(key);
return m.put(key, value);
}
public V remove(Object key) {
K k = (K)key;
return (!inBounds(k)) ? null : m.remove(k);
}
public int size() {
long count = 0;
for (ConcurrentSkipListMap.Node<K,V> n = loNode();
isBeforeEnd(n);
n = n.next) {
if (n.getValidValue() != null)
++count;
}
return count >= Integer.MAX_VALUE ? Integer.MAX_VALUE : (int)count;
}
public boolean isEmpty() {
return !isBeforeEnd(loNode());
}
public boolean containsValue(Object value) {
if (value == null)
throw new NullPointerException();
for (ConcurrentSkipListMap.Node<K,V> n = loNode();
isBeforeEnd(n);
n = n.next) {
V v = n.getValidValue();
if (v != null && value.equals(v))
return true;
}
return false;
}
public void clear() {
for (ConcurrentSkipListMap.Node<K,V> n = loNode();
isBeforeEnd(n);
n = n.next) {
if (n.getValidValue() != null)
m.remove(n.key);
}
}
/* ---------------- ConcurrentMap API methods -------------- */
public V putIfAbsent(K key, V value) {
checkKeyBounds(key);
return m.putIfAbsent(key, value);
}
public boolean remove(Object key, Object value) {
K k = (K)key;
return inBounds(k) && m.remove(k, value);
}
public boolean replace(K key, V oldValue, V newValue) {
checkKeyBounds(key);
return m.replace(key, oldValue, newValue);
}
public V replace(K key, V value) {
checkKeyBounds(key);
return m.replace(key, value);
}
/* ---------------- SortedMap API methods -------------- */
public Comparator<? super K> comparator() {
Comparator<? super K> cmp = m.comparator();
if (isDescending)
return Collections.reverseOrder(cmp);
else
return cmp;
}
/**
* Utility to create submaps, where given bounds override
* unbounded(null) ones and/or are checked against bounded ones.
*/
private SubMap<K,V> newSubMap(K fromKey,
boolean fromInclusive,
K toKey,
boolean toInclusive) {
if (isDescending) { // flip senses
K tk = fromKey;
fromKey = toKey;
toKey = tk;
boolean ti = fromInclusive;
fromInclusive = toInclusive;
toInclusive = ti;
}
if (lo != null) {
if (fromKey == null) {
fromKey = lo;
fromInclusive = loInclusive;
}
else {
int c = m.compare(fromKey, lo);
if (c < 0 || (c == 0 && !loInclusive && fromInclusive))
throw new IllegalArgumentException("key out of range");
}
}
if (hi != null) {
if (toKey == null) {
toKey = hi;
toInclusive = hiInclusive;
}
else {
int c = m.compare(toKey, hi);
if (c > 0 || (c == 0 && !hiInclusive && toInclusive))
throw new IllegalArgumentException("key out of range");
}
}
return new SubMap<K,V>(m, fromKey, fromInclusive,
toKey, toInclusive, isDescending);
}
public SubMap<K,V> subMap(K fromKey,
boolean fromInclusive,
K toKey,
boolean toInclusive) {
if (fromKey == null || toKey == null)
throw new NullPointerException();
return newSubMap(fromKey, fromInclusive, toKey, toInclusive);
}
public SubMap<K,V> headMap(K toKey,
boolean inclusive) {
if (toKey == null)
throw new NullPointerException();
return newSubMap(null, false, toKey, inclusive);
}
public SubMap<K,V> tailMap(K fromKey,
boolean inclusive) {
if (fromKey == null)
throw new NullPointerException();
return newSubMap(fromKey, inclusive, null, false);
}
public SubMap<K,V> subMap(K fromKey, K toKey) {
return subMap(fromKey, true, toKey, false);
}
public SubMap<K,V> headMap(K toKey) {
return headMap(toKey, false);
}
public SubMap<K,V> tailMap(K fromKey) {
return tailMap(fromKey, true);
}
public SubMap<K,V> descendingMap() {
return new SubMap<K,V>(m, lo, loInclusive,
hi, hiInclusive, !isDescending);
}
/* ---------------- Relational methods -------------- */
public Map.Entry<K,V> ceilingEntry(K key) {
return getNearEntry(key, (m.GT|m.EQ));
}
public K ceilingKey(K key) {
return getNearKey(key, (m.GT|m.EQ));
}
public Map.Entry<K,V> lowerEntry(K key) {
return getNearEntry(key, (m.LT));
}
public K lowerKey(K key) {
return getNearKey(key, (m.LT));
}
public Map.Entry<K,V> floorEntry(K key) {
return getNearEntry(key, (m.LT|m.EQ));
}
public K floorKey(K key) {
return getNearKey(key, (m.LT|m.EQ));
}
public Map.Entry<K,V> higherEntry(K key) {
return getNearEntry(key, (m.GT));
}
public K higherKey(K key) {
return getNearKey(key, (m.GT));
}
public K firstKey() {
return isDescending ? highestKey() : lowestKey();
}
public K lastKey() {
return isDescending ? lowestKey() : highestKey();
}
public Map.Entry<K,V> firstEntry() {
return isDescending ? highestEntry() : lowestEntry();
}
public Map.Entry<K,V> lastEntry() {
return isDescending ? lowestEntry() : highestEntry();
}
public Map.Entry<K,V> pollFirstEntry() {
return isDescending ? removeHighest() : removeLowest();
}
public Map.Entry<K,V> pollLastEntry() {
return isDescending ? removeLowest() : removeHighest();
}
/* ---------------- Submap Views -------------- */
public NavigableSet<K> keySet() {
KeySet<K> ks = keySetView;
return (ks != null) ? ks : (keySetView = new KeySet(this));
}
public NavigableSet<K> navigableKeySet() {
KeySet<K> ks = keySetView;
return (ks != null) ? ks : (keySetView = new KeySet(this));
}
public Collection<V> values() {
Collection<V> vs = valuesView;
return (vs != null) ? vs : (valuesView = new Values(this));
}
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es = entrySetView;
return (es != null) ? es : (entrySetView = new EntrySet(this));
}
public NavigableSet<K> descendingKeySet() {
return descendingMap().navigableKeySet();
}
Iterator<K> keyIterator() {
return new SubMapKeyIterator();
}
Iterator<V> valueIterator() {
return new SubMapValueIterator();
}
Iterator<Map.Entry<K,V>> entryIterator() {
return new SubMapEntryIterator();
}
/**
* Variant of main Iter class to traverse through submaps.
*/
abstract class SubMapIter<T> implements Iterator<T> {
/** the last node returned by next() */
Node<K,V> lastReturned;
/** the next node to return from next(); */
Node<K,V> next;
/** Cache of next value field to maintain weak consistency */
V nextValue;
SubMapIter() {
for (;;) {
next = isDescending ? hiNode() : loNode();
if (next == null)
break;
Object x = next.value;
if (x != null && x != next) {
if (! inBounds(next.key))
next = null;
else
nextValue = (V) x;
break;
}
}
}
public final boolean hasNext() {
return next != null;
}
final void advance() {
if (next == null)
throw new NoSuchElementException();
lastReturned = next;
if (isDescending)
descend();
else
ascend();
}
private void ascend() {
for (;;) {
next = next.next;
if (next == null)
break;
Object x = next.value;
if (x != null && x != next) {
if (tooHigh(next.key))
next = null;
else
nextValue = (V) x;
break;
}
}
}
private void descend() {
for (;;) {
next = m.findNear(lastReturned.key, LT);
if (next == null)
break;
Object x = next.value;
if (x != null && x != next) {
if (tooLow(next.key))
next = null;
else
nextValue = (V) x;
break;
}
}
}
public void remove() {
Node<K,V> l = lastReturned;
if (l == null)
throw new IllegalStateException();
m.remove(l.key);
lastReturned = null;
}
}
final class SubMapValueIterator extends SubMapIter<V> {
public V next() {
V v = nextValue;
advance();
return v;
}
}
final class SubMapKeyIterator extends SubMapIter<K> {
public K next() {
Node<K,V> n = next;
advance();
return n.key;
}
}
final class SubMapEntryIterator extends SubMapIter<Map.Entry<K,V>> {
public Map.Entry<K,V> next() {
Node<K,V> n = next;
V v = nextValue;
advance();
return new AbstractMap.SimpleImmutableEntry<K,V>(n.key, v);
}
}
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long headOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class k = ConcurrentSkipListMap.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
} catch (Exception e) {
throw new Error(e);
}
}
}
下面从ConcurrentSkipListMap的添加,删除,获取这3个方面对它进行分析。
4.1 添加
下面以put(K key, V value)为例,对ConcurrentSkipListMap的添加方法进行说明。
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
实际上,put()是通过doPut()将key-value键值对添加到ConcurrentSkipListMap中的。
doPut()的源码如下:
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为“key的前继节点的后继节点”,即n应该是“插入节点”的“后继节点”
Node<K,V> n = b.next;
for (;;) {
if (n != null) {
Node<K,V> f = n.next;
// 如果两次获得的b.next不是相同的Node,就跳转到”外层for循环“,重新获得b和n后再遍历。
if (n != b.next)
break;
// v是“n的值”
Object v = n.value;
// 当n的值为null(意味着其它线程删除了n);此时删除b的下一个节点,然后跳转到”外层for循环“,重新获得b和n后再遍历。
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// 如果其它线程删除了b;则跳转到”外层for循环“,重新获得b和n后再遍历。
if (v == n || b.value == null) // b is deleted
break;
// 比较key和n.key
int c = key.compareTo(n.key);
if (c > 0) {
b = n;
n = f;
continue;
}
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
// 新建节点(对应是“要插入的键值对”)
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 设置“b的后继节点”为z
if (!b.casNext(n, z))
break; // 多线程情况下,break才可能发生(其它线程对b进行了操作)
// 随机获取一个level
// 然后在“第1层”到“第level层”的链表中都插入新建节点
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
说明:doPut() 的作用就是将键值对添加到“跳表”中。
要想搞清doPut(),首先要弄清楚它的主干部分 —— 我们先单纯的只考虑“单线程的情况下,将key-value添加到跳表中”,即忽略“多线程相关的内容”。它的流程如下:
第1步:找到“插入位置”。
即,找到“key的前继节点(b)”和“key的后继节点(n)”;key是要插入节点的键。
第2步:新建并插入节点。
即,新建节点z(key对应的节点),并将新节点z插入到“跳表”中(设置“b的后继节点为z”,“z的后继节点为n”)。
第3步:更新跳表。
即,随机获取一个level,然后在“跳表”的第1层~第level层之间,每一层都插入节点z;在第level层之上就不再插入节点了。若level数值大于“跳表的层次”,则新建一层。
主干部分“对应的精简后的doPut()的代码”如下(仅供参考):
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为key的后继节点
Node<K,V> n = b.next;
for (;;) {
// 新建节点(对应是“要被插入的键值对”)
Node<K,V> z = new Node<K,V>(kkey, value, n);
// 设置“b的后继节点”为z
b.casNext(n, z);
// 随机获取一个level
// 然后在“第1层”到“第level层”的链表中都插入新建节点
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
理清主干之后,剩余的工作就相对简单了。主要是上面几步的对应算法的具体实现,以及多线程相关情况的处理!
4.2 删除
下面以remove(Object key)为例,对ConcurrentSkipListMap的删除方法进行说明。
public V remove(Object key) {
return doRemove(key, null);
}
实际上,remove()是通过doRemove()将ConcurrentSkipListMap中的key对应的键值对删除的。
doRemove()的源码如下:
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到“key的前继节点”
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return null;
// f是“当前节点n的后继节点”
Node<K,V> f = n.next;
// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (n != b.next) // inconsistent read
break;
// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// 如果“前继节点b”被删除(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c < 0)
return null;
if (c > 0) {
b = n;
n = f;
continue;
}
// 以下是c=0的情况
if (value != null && !value.equals(v))
return null;
// 设置“当前节点n”的值为null
if (!n.casValue(v, null))
break;
// 设置“b的后继节点”为f
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // Retry via findNode
else {
// 清除“跳表”中每一层的key节点
findPredecessor(key); // Clean index
// 如果“表头的右索引为空”,则将“跳表的层次”-1。
if (head.right == null)
tryReduceLevel();
}
return (V)v;
}
}
}
说明:doRemove()的作用是删除跳表中的节点。
和doPut()一样,我们重点看doRemove()的主干部分,了解主干部分之后,其余部分就非常容易理解了。下面是“单线程的情况下,删除跳表中键值对的步骤”:
第1步:找到“被删除节点的位置”。
即,找到“key的前继节点(b)”,“key所对应的节点(n)”,“n的后继节点f”;key是要删除节点的键。
第2步:删除节点。
即,将“key所对应的节点n”从跳表中移除 -- 将“b的后继节点”设为“f”!
第3步:更新跳表。
即,遍历跳表,删除每一层的“key节点”(如果存在的话)。如果删除“key节点”之后,跳表的层次需要-1;则执行相应的操作!
主干部分“对应的精简后的doRemove()的代码”如下(仅供参考):
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到“key的前继节点”
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
// f是“当前节点n的后继节点”
Node<K,V> f = n.next;
// 设置“当前节点n”的值为null
n.casValue(v, null);
// 设置“b的后继节点”为f
b.casNext(n, f);
// 清除“跳表”中每一层的key节点
findPredecessor(key);
// 如果“表头的右索引为空”,则将“跳表的层次”-1。
if (head.right == null)
tryReduceLevel();
return (V)v;
}
}
}
4.3 获取
下面以get(Object key)为例,对ConcurrentSkipListMap的获取方法进行说明。
public V get(Object key) {
return doGet(key);
}
doGet的源码如下:
private V doGet(Object okey) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// 找到“key对应的节点”
Node<K,V> n = findNode(key);
if (n == null)
return null;
Object v = n.value;
if (v != null)
return (V)v;
}
}
说明:doGet()是通过findNode()找到并返回节点的。
private Node<K,V> findNode(Comparable<? super K> key) {
for (;;) {
// 找到key的前继节点
Node<K,V> b = findPredecessor(key);
// 设置n为“b的后继节点”(即若key存在于“跳表中”,n就是key对应的节点)
Node<K,V> n = b.next;
for (;;) {
// 如果“n为null”,则跳转中不存在key对应的节点,直接返回null。
if (n == null)
return null;
Node<K,V> f = n.next;
// 如果两次读取到的“b的后继节点”不同(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (n != b.next) // inconsistent read
break;
Object v = n.value;
// 如果“当前节点n的值”变为null(其它线程操作了该跳表),则返回到“外层for循环”重新遍历。
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
// 若n是当前节点,则返回n。
int c = key.compareTo(n.key);
if (c == 0)
return n;
// 若“节点n的key”小于“key”,则说明跳表中不存在key对应的节点,返回null
if (c < 0)
return null;
// 若“节点n的key”大于“key”,则更新b和n,继续查找。
b = n;
n = f;
}
}
}
说明:findNode(key)的作用是在返回跳表中key对应的节点;存在则返回节点,不存在则返回null。
先弄清函数的主干部分,即抛开“多线程相关内容”,单纯的考虑单线程情况下,从跳表获取节点的算法。
第1步:找到“被删除节点的位置”。
根据findPredecessor()定位key所在的层次以及找到key的前继节点(b),然后找到b的后继节点n。
第2步:根据“key的前继节点(b)”和“key的前继节点的后继节点(n)”来定位“key对应的节点”。
具体是通过比较“n的键值”和“key”的大小。如果相等,则n就是所要查找的键。
5. ConcurrentSkipListMap示例
import java.util.*;
import java.util.concurrent.*;
/*
* ConcurrentSkipListMap是“线程安全”的哈希表,而TreeMap是非线程安全的。
*
* 下面是“多个线程同时操作并且遍历map”的示例
* (01) 当map是ConcurrentSkipListMap对象时,程序能正常运行。
* (02) 当map是TreeMap对象时,程序会产生ConcurrentModificationException异常。
*
* @author skywang
*/
public class ConcurrentSkipListMapDemo1 {
// TODO: map是TreeMap对象时,程序会出错。
//private static Map<String, String> map = new TreeMap<String, String>();
private static Map<String, String> map = new ConcurrentSkipListMap<String, String>();
public static void main(String[] args) {
// 同时启动两个线程对map进行操作!
new MyThread("a").start();
new MyThread("b").start();
}
private static void printAll() {
String key, value;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();
value = (String)entry.getValue();
System.out.print("("+key+", "+value+"), ");
}
System.out.println();
}
private static class MyThread extends Thread {
MyThread(String name) {
super(name);
}
@Override
public void run() {
int i = 0;
while (i++ < 6) {
// “线程名” + "序号"
String val = Thread.currentThread().getName()+i;
map.put(val, "0");
// 通过“Iterator”遍历map。
printAll();
}
}
}
}
(某一次)运行结果:
(a1, 0), (a1, 0), (b1, 0), (b1, 0),
(a1, 0), (b1, 0), (b2, 0),
(a1, 0), (a1, 0), (a2, 0), (a2, 0), (b1, 0), (b1, 0), (b2, 0), (b2, 0), (b3, 0),
(b3, 0), (a1, 0),
(a2, 0), (a3, 0), (a1, 0), (b1, 0), (a2, 0), (b2, 0), (a3, 0), (b3, 0), (b1, 0), (b4, 0),
(b2, 0), (a1, 0), (b3, 0), (a2, 0), (b4, 0),
(a3, 0), (a1, 0), (a4, 0), (a2, 0), (b1, 0), (a3, 0), (b2, 0), (a4, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0),
(b3, 0), (a1, 0), (b4, 0), (a2, 0), (b5, 0),
(a3, 0), (a1, 0), (a4, 0), (a2, 0), (a5, 0), (a3, 0), (b1, 0), (a4, 0), (b2, 0), (a5, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0), (b3, 0), (b6, 0),
(b4, 0), (a1, 0), (b5, 0), (a2, 0), (b6, 0),
(a3, 0), (a4, 0), (a5, 0), (a6, 0), (b1, 0), (b2, 0), (b3, 0), (b4, 0), (b5, 0), (b6, 0),
结果说明:
示例程序中,启动两个线程(线程a和线程b)分别对ConcurrentSkipListMap进行操作。以线程a而言,它会先获取“线程名”+“序号”,然后将该字符串作为key,将“0”作为value,插入到ConcurrentSkipListMap中;接着,遍历并输出ConcurrentSkipListMap中的全部元素。 线程b的操作和线程a一样,只不过线程b的名字和线程a的名字不同。
当map是ConcurrentSkipListMap对象时,程序能正常运行。如果将map改为TreeMap时,程序会产生ConcurrentModificationException异常。